
The Fragile Trust Chain: Why One Bad Citation Makes You Invisible to AI
Last Updated: May 5, 2026
AI engines don't trust your website. Not alone. They're cross-referencing everything you claim against dozens of external sources—data aggregators like Data Axle and Foursquare, major platforms like Google Business Profile and Apple Maps, industry-specific directories. When those sources conflict, you lose. Matching information across sources? AI marks you trustworthy. Contradictions—an old address on one directory, a disconnected phone number on another, a misspelled business name on a third? You're flagged as unreliable and skipped.
This isn't a ranking penalty. It's binary trust failure. Traditional search engines could show you on page one even with messy citations because they were building a list of options for users to evaluate. AI answer engines are making a singular recommendation on behalf of the user. If your entity trust is fragile—if the data chain supporting your business identity has even one broken link—the AI engine doesn't risk recommending you. It defaults to the competitor whose citations present a clean, unified identity across all validation points.
Most practices have no idea which citations are breaking them. Not which aggregators AI checks. Not where the conflicts live. Not how long fixes take to propagate. They're flying blind—and losing ground every month they don't know it. A chiropractor might update their Google Business Profile and assume the problem is solved, unaware that an outdated listing on a secondary aggregator is still feeding bad data into the AI's validation system months later.
Why One Incorrect Citation Breaks the Entire Chain
Your citations aren't a list of places you're mentioned online.
They're a chain. Each link connects your practice to AI's knowledge graph. Google Business Profile. Data Axle. Foursquare. Healthgrades. Apple Maps. Every single directory and aggregator where your business information lives.
AI engines don't check one source and call it good. They check all of them. They're building consensus. Looking for alignment. Validating that the same information appears consistently across independent sources.
One broken link shatters the entire chain.
Here's why: AI interprets data conflicts as credibility failures. Your address is correct on Google but wrong on Data Axle? AI doesn't know which source to trust. Phone number works on your website but disconnected on Healthgrades? AI sees an identity mismatch. Business name formatted differently across ten directories? AI questions whether these listings even represent the same entity.
The result isn't a ranking drop.
It's trust collapse.
AI engines making singular recommendations can't afford to guess. They need certainty. When your citation chain has conflicts, you don't get the benefit of the doubt — you get skipped entirely.
The competitor whose data presents a unified, verifiable identity? That's who gets recommended.
Most practices don't realize this is happening because the failure is invisible. You're not on page two. You're not in the results at all. AI ran its trust calculation, found conflicts in your entity validation, and moved on.
Why Agencies Treat This Like a Data Entry Task
Most agencies position citation management as a commodity checklist.
Update your Google listing. Submit to a few directories. Done.
They frame it as minor local SEO optimization — something you do once and forget about. A data entry project priced at a few hundred bucks, bundled into a retainer, handled by an offshore VA copying and pasting your NAP into submission forms.
Here's what that approach misses entirely:
Citations aren't a ranking factor anymore. They're an entity validation layer.
For traditional search, citations influenced your position in the map pack. Messy citations meant you'd show up seventh instead of third. Annoying, sure. Not fatal.
For AI answer engines, citations determine whether you're recognized as a legitimate business entity at all.
The stakes shifted from "where do I rank in the list" to "does AI believe I exist."
That's not a data entry task. That's foundational infrastructure. It's the difference between your practice being visible to AI or being filtered out before the recommendation process even starts.
Agencies treating this like a commodity checklist fundamentally misunderstand what citations do in the AI era.
They're optimizing for an algorithm that's already been replaced. Managing the wrong problem.
And practices are paying for citation cleanup that doesn't address the actual mechanism causing their invisibility — because the cleanup is focused on local pack rankings, not entity trust validation.
The Old Rule vs. The New Stakes
The old rule: citations help you rank higher in local search results.
You'd optimize your Name, Address, Phone Number across directories. Build some backlinks. Get listed in industry-specific platforms. The goal was appearing in the top three map pack results when someone searched "chiropractor near me."
Messy citations? You might rank fifth instead of first.
Frustrating. But you were still in the game. Patients could still find you if they scrolled.
The new stakes: citations determine whether AI recognizes you as a credible entity worthy of recommendation.
AI engines don't rank you in a list. They make a verdict.
When someone asks ChatGPT or Gemini who the best chiropractor in their area is, the AI either says your name or it doesn't. There's no second page. No "scroll to see more options."
Messy citations don't hurt your ranking anymore.
They disqualify you from consideration.
| Old Citation Management (SEO Era) | New Citation Validation (AI Era) | Impact of Errors |
|---|---|---|
| Goal: Rank higher in local map pack results | Goal: Build entity trust for AI recommendation | Old: Drop from position 3 to position 7 |
| Audience: Users evaluating a list of options | Audience: AI making a singular recommendation on behalf of the user | New: Removed from consideration entirely |
| Mechanism: Backlinks and directory presence influence ranking signals | Mechanism: Cross-source validation establishes entity legitimacy | Old: Still visible, fewer clicks |
| Tolerance for errors: Low impact — still appears in results | Tolerance for errors: Zero — conflicts trigger trust failure | New: Invisible — not mentioned in the answer |
The shift isn't subtle. It's binary.
Traditional SEO allowed for messy citation profiles because users were still doing the evaluation. They'd see your listing, click through, decide for themselves.
AI answer engines are doing the evaluation for the user.
They're not presenting options. They're making a recommendation. And they won't recommend a business whose identity they can't verify with confidence.
That's the new stakes.
One bad citation doesn't cost you a few positions in the rankings. It costs you the entire recommendation.
How AI Engines Validate Your Business Identity
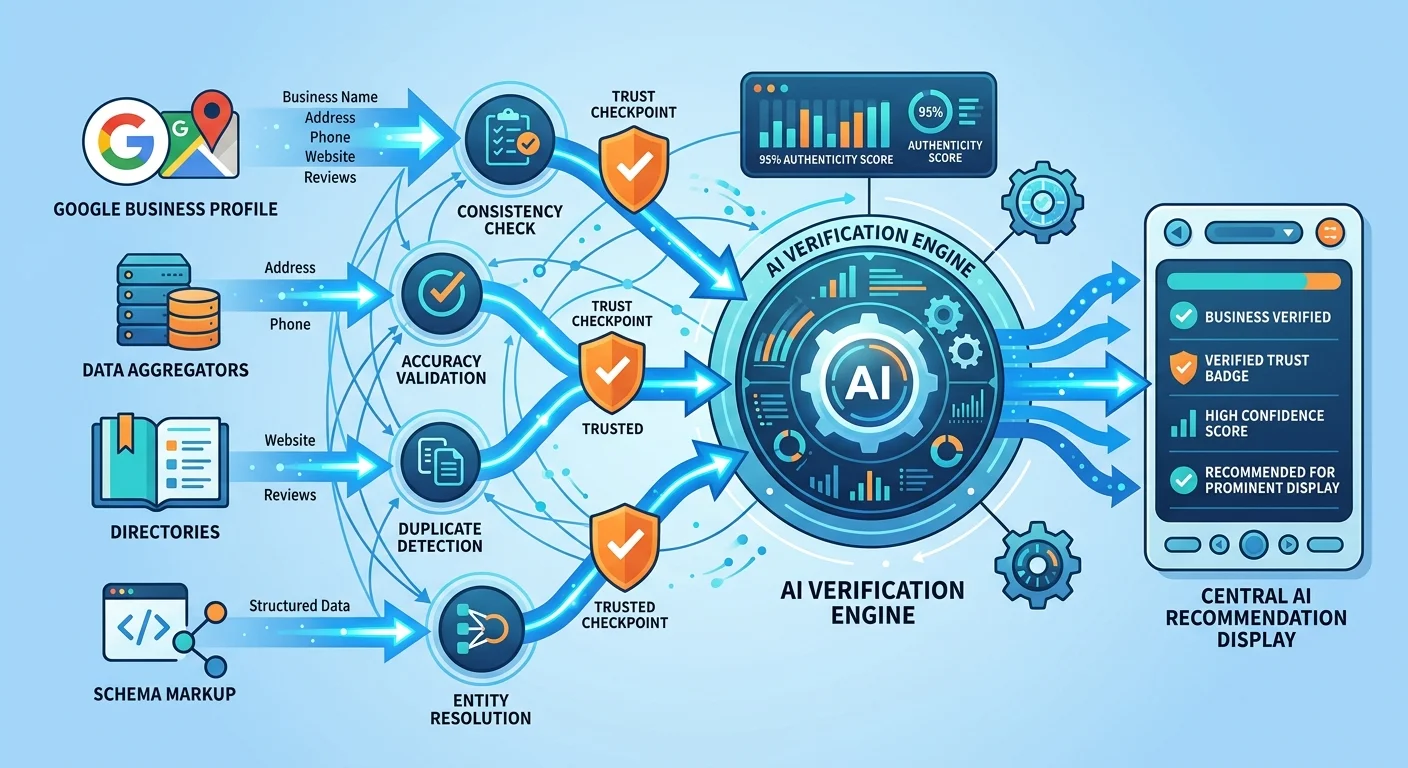
AI engines don't take your word for it.
When ChatGPT or Gemini evaluates whether to recommend your practice, they're not just reading your website. They're running a cross-reference check across dozens of independent sources to verify your business identity.
Think of it like a background check.
The AI is asking: Does this business exist? Is the information consistent? Can I trust this entity enough to stake my credibility on recommending it?
The validation process works in three steps:
Step 1: Data Collection
AI crawls your website. Reads your schema markup. Checks your Google Business Profile. Scans major data aggregators like Data Axle and Foursquare. Reviews directory listings on platforms like Healthgrades and Yelp. Indexes industry-specific sources relevant to your market.
It's not checking one or two places.
It's checking every place where your business information appears online.
Step 2: Consensus Building
AI compares the data it collected. Name, address, phone number, business category, hours, services offered.
It's looking for alignment.
When the same information appears consistently across multiple independent sources, AI builds confidence that the data is accurate.
According to the U.S. Small Business Administration, accurate and consistent business information across online directories is foundational for local visibility — not just for search engines, but for any system trying to validate a business's legitimacy.
Step 3: Trust Calculation
AI assigns weight to different sources based on their authority tier.
A conflict on a Tier 1 aggregator like Data Axle carries more weight than a conflict on a Tier 3 niche directory. But even small conflicts can break trust if they appear on sources AI considers credible validators.
When the data aligns, AI marks your entity as trustworthy.
When conflicts exist, AI downgrades your credibility or removes you from consideration entirely.
This isn't a ranking algorithm. It's a verification protocol.
And the standard isn't "mostly correct." It's "consistently verifiable across independent sources."
If you want to understand more about Gerek Allen and iTech Valet and why we've built an entire system around entity trust validation, it's because this verification process is the single most important gatekeeper determining who AI recommends.
The Three-Layer Validation Model
Not all citation sources carry equal weight.
AI engines evaluate sources in tiers based on authority, reach, and trustworthiness.
A conflict on a Tier 1 aggregator can disqualify you instantly. A conflict on a Tier 3 niche directory might be ignored if everything else aligns.
Here's how the tiers break down:
| Tier | Source Examples | Weight in Trust Calculation |
|---|---|---|
| Tier 1: Core Aggregators | Data Axle, Foursquare, Factual, Neustar Localeze | Highest — these feed data to hundreds of downstream directories and platforms. Conflicts here propagate across the entire ecosystem. |
| Tier 2: Platform-Specific Sources | Google Business Profile, Apple Maps, Bing Places, Facebook Business | High — these are direct-to-consumer platforms AI engines prioritize for verification. Conflicts here are visible to both AI and patients. |
| Tier 3: Industry Directories | Healthgrades, Zocdoc, Vitals, WebMD, local chamber listings | Moderate — relevant for niche validation. AI uses these to confirm specialization and local presence, but conflicts here are less critical if Tiers 1 and 2 are clean. |
Why Tier 1 matters most:
Data aggregators like Data Axle and Foursquare don't just list your business.
They syndicate your information to hundreds of other platforms.
If your data is wrong at the aggregator level, that incorrect information cascades downstream to directories you've never heard of — and AI engines validating your entity across those directories will see the same conflict replicated everywhere.
Fixing a Tier 1 source corrects the root of the problem.
Fixing individual Tier 3 directories without addressing the aggregator is like mopping the floor while the pipe is still leaking.
Why Tier 2 matters for speed:
Platforms like Google Business Profile and Apple Maps are updated frequently and crawled aggressively by AI engines.
Correcting these sources delivers the fastest trust signal improvements because AI engines check them constantly.
But if your Tier 1 aggregators still have bad data, those platforms will eventually resync with the aggregator feed and reintroduce the conflict.
Why Tier 3 still matters:
Industry-specific directories like Healthgrades and Zocdoc serve as niche validators.
When AI engines are evaluating healthcare providers, they weight these sources more heavily because they're domain-relevant.
A conflict here won't necessarily disqualify you if your Tier 1 and Tier 2 citations are clean. But if you're competing against another chiropractor whose citations are flawless across all three tiers, AI will favor the entity with deeper, cleaner validation signals.
The validation model isn't "get listed everywhere."
It's "get listed accurately on the sources AI engines trust most — and eliminate conflicts at every tier."
What Counts as a "Conflict"
AI engines interpret conflicts broadly.
You might think a conflict means your address is completely wrong — like listing a different city.
That's a conflict, sure.
But so is a lot of smaller stuff you probably aren't monitoring.
Here's what counts:
- NAP inconsistencies — Name, Address, Phone Number variations across sources. "Dr. John Smith Chiropractic" on one platform and "John Smith DC" on another. That's a conflict. Same business, different identity formatting.
- Outdated information — Your practice moved two years ago and you updated Google, but Data Axle still lists your old address. AI sees two different addresses for the same entity. Conflict.
- Disconnected phone numbers — You changed your main line six months ago. Website and Google listing are updated. But Healthgrades, Yelp, and three other directories still show the old number. AI calls the old number, gets a disconnect message, flags the entity as unverifiable.
- Variations in business name formatting — "Smith Family Chiropractic" versus "Smith Family Chiropractic Center" versus "Smith Chiropractic." Humans understand those are the same business. AI sees three different entity names and can't confirm which one is authoritative.
- Inconsistent service categories — Google says you're a chiropractor. Yelp says you're a wellness center. WebMD says you're a pain management clinic. AI doesn't know which category to trust, so it doesn't trust any of them fully.
- Mismatched hours or service descriptions — One directory says you're open Saturdays. Another says you're closed. AI doesn't know which source is current. That uncertainty downgrades your entity trust.
BrightLocal found that consumers lose trust in businesses with incorrect or inconsistent online information.
AI engines are proxies for consumers.
They interpret the same inconsistencies as credibility failures.
The kicker: most of these conflicts aren't intentional.
You didn't deliberately list different phone numbers. You moved, updated the obvious places, and assumed the rest would sync. Or you rebranded, changed your business name slightly, and didn't realize old listings would persist with the previous name indefinitely.
AI doesn't care whether the conflict was intentional.
It just sees data that doesn't align. And when data doesn't align, entity trust breaks.
The Citation Audit You're Not Running
Most practices think they're monitoring their citations because they check Google Business Profile once a month.
They're not.
Google is one source. AI engines are checking dozens. And the sources causing the most entity trust damage are the ones you're not even aware exist.
Here's the gap:
You know about Google Business Profile, Yelp, Healthgrades, maybe Facebook Business. You've logged into those platforms. Updated your information. Assume that covers it.
AI engines are also checking Data Axle, Foursquare, Neustar Localeze, Factual, Apple Maps, Bing Places, Whitepages, YP.com, Superpages, CitySearch, local chamber listings, industry-specific aggregators, and hundreds of niche directories that syndicate data from Tier 1 aggregators.
You don't have logins for most of those sources.
You didn't create those listings. They were auto-generated when a data aggregator scraped public business records or pulled information from another directory.
And because you didn't create them, you're not monitoring them.
Which means when your business information changes — you move locations, update your phone number, rebrand — those auto-generated listings don't update.
They sit there feeding outdated data into AI's validation system indefinitely.
That's where the trust chain breaks.
Not on the platforms you're watching. On the ones you don't know you're listed on.
The Sources AI Checks That You Don't
Here's what's probably happening right now without your knowledge:
Secondary data aggregators are still listing your old address from three years ago because no one ever submitted a correction to Neustar Localeze or Factual after your practice relocated.
Auto-generated directory listings were created when you opened your practice and have never been touched since.
YP.com, Superpages, Whitepages — they all have listings for you. None of them are current.
Legacy marketing campaign directories from that one SEO agency you hired five years ago.
They submitted your practice to fifty niche directories as part of a "citation building" package. You canceled the service. The listings are still live. Half of them have wrong information.
Franchise or multi-location aggregators if you're part of a larger network.
These pull data from corporate sources that may not reflect your local updates. AI sees your individual practice listing with one address and the franchise aggregator listing with a different address. Conflict.
Industry-specific platforms like state licensing boards, professional associations, or healthcare directories that pull data from public records.
You updated your contact info with the state board, but the directory that syndicates board data hasn't refreshed its feed in six months.
These aren't obscure sources.
AI engines validate against them because they're considered authoritative in specific contexts. And every single one of them can introduce a conflict that breaks your entity trust.
The practices that understand how to anchor your entity in the knowledge graph aren't just managing the obvious platforms.
They're auditing the invisible sources where AI engines are finding conflicting data.
How Long Bad Data Lives in the System
You fixed it.
Updated your Google listing. Submitted corrections to a few directories. Problem solved, right?
Not even close.
Here's the reality: submitting a correction is step one. Getting that correction to propagate through AI's knowledge graph is step two — and it takes weeks or months.
Data aggregators don't update in real time.
They operate on crawl schedules. Some refresh monthly. Some quarterly. Some only update when a critical mass of sources report the same correction.
So you submit a correction to Data Axle in January. They process it in February. It syndicates to downstream directories in March. AI engines recrawl those directories in April.
And maybe — maybe — by May, AI's internal knowledge graph reflects the updated information.
That's a four-month lag between "I fixed it" and "AI recognizes it's fixed."
And that assumes you only had one bad citation to correct.
If you have conflicts across ten sources, and each one operates on a different update schedule, you're looking at a rolling correction process that can take six months or longer before entity trust fully rebuilds.
Meanwhile, every single day that bad data is still live somewhere in the ecosystem, AI engines running validation checks are seeing the conflict and choosing not to recommend you.
Moz explains how search and answer engines use citation data from various sources to validate a business's existence and legitimacy — but the validation happens at the speed of the slowest data source in the chain.
This is why "I updated my Google listing and nothing changed" is such a common frustration.
Google updated. AI's knowledge graph hasn't recrawled all the other sources yet.
You're still invisible because the trust chain is still broken elsewhere.
The practices that win AI recommendations aren't the ones that react to problems.
They're the ones that proactively manage citations before conflicts appear — because they understand that fixing entity trust is measured in months, not days.
Where Most Practices Lose Entity Trust
Most citation failures aren't malicious.
They're accidental.
You relocated. Rebranded. Changed phone carriers. Merged with another practice. Normal business operations that happen to chiropractors all the time.
The problem: every single one of those changes creates dozens of citation conflicts if not managed systematically.
And most practices don't realize the conflicts exist until they're already invisible to AI.
Here are the most common failure points I've seen that shatter entity trust:
- Practice relocations that update Google and the website but miss secondary aggregators
- Phone number changes that propagate slowly or not at all through directory networks
- Business name variations from rebranding efforts that leave legacy listings with the old name
- Multi-location conflicts where franchise or corporate data contradicts individual location data
- Legacy directory listings from old marketing campaigns that were never deactivated
Every one of these is fixable.
But most practices don't know they need fixing until after the damage is done — because the citation conflicts are invisible until AI stops recommending you.
Understanding why commodity agencies can't build proprietary authority starts here.
Agencies treating citations like a one-time submission task aren't monitoring for these failure points. They're not tracking propagation delays. They're not auditing the sources AI engines actually check.
They're optimizing for the old game.
And the old game doesn't matter anymore.
The Post-Relocation Gap
Practice relocations create the most severe citation conflicts.
Here's why:
When you move, you update the obvious platforms immediately. New address on the website. New address on Google Business Profile. Maybe new signage, new business cards, new patient intake forms.
You think you're done.
Meanwhile, Data Axle still has your old address. So does Foursquare. And Neustar Localeze. And every single directory that syndicates data from those aggregators — which is hundreds of platforms.
Now AI engines are validating your entity.
Your website says one address. Google says the same address. Good so far.
But Data Axle says a different address. And so does YP.com. And Superpages. And CitySearch. And forty other directories you've never heard of that are all pulling from the same outdated aggregator feed.
AI sees two addresses for the same business.
It doesn't know which one is current. So it doesn't recommend you.
The post-relocation gap isn't measured in days. It's measured in months.
Even if you submit corrections to the aggregators immediately, those corrections take weeks to process. Then they take more weeks to syndicate downstream. Then AI engines have to recrawl all those downstream directories to pick up the updates.
I've watched practices stay invisible for six months after a relocation because they updated Google and assumed the rest would follow.
It didn't.
And every day that old address was live somewhere in the ecosystem, AI engines were seeing a trust failure and choosing competitors with clean, consistent data.
The practices that manage relocations correctly don't just update the obvious platforms.
They submit corrections to every Tier 1 aggregator before the move even happens. They monitor downstream propagation. They verify the updates landed across the full citation ecosystem.
They treat the relocation like the entity trust emergency it is — because they understand that AI doesn't wait for you to figure it out.
It just recommends someone else.
The Phone Number That Never Dies
Phone number changes are citation killers.
You switch carriers. Get a new main line. Update your website and Google Business Profile immediately. Redirect the old number for a few months, then cancel the service entirely.
Problem solved.
Except it's not.
Because fifty directories you didn't know existed still list the old number.
And AI engines validating your entity are calling that old number to verify your business is active.
They get a disconnect message.
Now AI doesn't just see a data conflict. It sees a defunct business.
A disconnected phone number signals that the entity may no longer be operational — which is a catastrophic trust failure.
Even worse: disconnected numbers often get reassigned.
Six months after you cancel that old line, it's assigned to someone else. Now AI calls the number, gets a random person who has no idea what your chiropractic practice is, and the entity validation fails even harder.
The old phone number doesn't just live in obscure directories.
It lives in Tier 1 aggregators that syndicate to hundreds of downstream platforms. Data Axle, Foursquare, Neustar Localeze — they all have long memory cycles.
If you don't proactively submit a correction, that old number stays in their database indefinitely.
And every platform that pulls data from those aggregators will keep listing the disconnected number until the aggregator updates.
Which means the conflict propagates across the entire ecosystem for months or years.
I've seen practices with spotless Google listings and current websites that are still invisible to AI because a disconnected phone number from three years ago is live on twenty directories they've never logged into.
The fix isn't complicated.
Submit phone number updates to every Tier 1 aggregator as soon as the change happens. Monitor downstream directories to verify the update propagated. Keep the old number active and forwarded for at least six months while the corrections process.
But most practices don't do that.
They update the obvious places and assume the rest will figure itself out.
It won't.
And AI engines won't wait for you to realize the problem before recommending a competitor whose phone number actually works.
The Franchise/Multi-Location Nightmare
Multi-location practices and franchises face a unique citation problem: hierarchical data conflicts.
Here's how it breaks:
Corporate or franchise headquarters maintains a master listing with centralized information. Individual locations maintain their own local listings with location-specific details.
AI engines see both.
And when they don't align, entity trust collapses.
Example: You're part of a chiropractic franchise. Corporate lists the main office address and a general 1-800 number. Your local listing shows your individual clinic address and direct line.
AI cross-references.
Sees two different addresses and two different phone numbers for entities that claim to be the same business. Flags it as a conflict.
Even if both listings are technically correct — one represents corporate, one represents your location — AI doesn't interpret context.
It sees mismatched data and downgrades trust.
Franchise systems make this worse by syndicating corporate data to Tier 1 aggregators without giving individual locations control over local updates.
So you submit corrections to your local Google listing, but Data Axle still shows the corporate information because that's what headquarters submitted to the aggregator network.
Now you're fighting your own franchise for citation accuracy.
And losing.
Multi-location practices without franchise affiliation have similar problems if they use a single business name across locations but don't clearly differentiate entities.
"Smith Chiropractic" with three locations looks like three different businesses to AI if the citations aren't structured to show they're related.
AI sees "Smith Chiropractic" at Address A with Phone Number A listed on Google. Then sees "Smith Chiropractic" at Address B with Phone Number B listed on Healthgrades. Then sees "Smith Chiropractic" at Address C with Phone Number C listed on Yelp.
Three entities? One entity with conflicting data?
AI doesn't know. So it doesn't recommend any of them.
The fix requires structured differentiation.
Each location needs a unique entity identity (e.g., "Smith Chiropractic — Downtown" vs. "Smith Chiropractic — Westside") with clearly defined NAP for each. Schema markup on the website needs to declare the relationship between locations. Citations need to be submitted individually for each location with no cross-contamination.
And if you're part of a franchise, you need corporate to cooperate — which most don't, because they're managing hundreds of locations and don't understand why individual citation accuracy matters for AI entity trust.
It's a nightmare.
And most practices stuck in it don't even realize the corporate-level data they can't control is the reason they're invisible.
| Common Citation Error | Example | AI Engine Interpretation |
|---|---|---|
| Old Address from Relocation | Website shows new address, Data Axle shows old address from 3 years ago | Two addresses = conflicting entity data. Trust downgraded. |
| Disconnected Phone Number | Google listing updated, YP.com still shows disconnected line from previous carrier | Disconnected number = defunct business. Entity flagged as inactive. |
| Business Name Variation | Google: "Smith Family Chiropractic" / Yelp: "Smith Chiropractic Center" | Different names = uncertain entity identity. Cannot confirm which is authoritative. |
| Franchise Hierarchy Conflict | Corporate listing shows HQ address, local listing shows individual clinic address | Two addresses for same business name = unresolved entity relationship. Trust failure. |
| Category Mismatch | Google: Chiropractor / WebMD: Pain Management Clinic / Yelp: Wellness Center | Conflicting categories = unclear specialization. AI cannot determine authoritative classification. |
What a Clean Trust Chain Actually Looks Like
A clean trust chain isn't aspirational.
It's operational.
It means AI engines cross-referencing your business information across fifty sources find the same data everywhere. No conflicts. No outdated listings. No disconnected numbers. No name variations.
Just consistent, verifiable identity signals that build confidence your entity is legitimate and authoritative.
Here's what that actually looks like in practice:
- Tier 1 aggregators are current and accurate — Data Axle, Foursquare, Neustar Localeze all show your correct NAP with no legacy data from previous addresses or phone numbers
- Platform-specific sources align perfectly — Google Business Profile, Apple Maps, Bing Places, Facebook all reflect the same information with identical formatting
- Industry directories are monitored and updated — Healthgrades, Zocdoc, Vitals, WebMD show current information and match the data on Tier 1 and Tier 2 sources
- Schema markup on your website reinforces citation data — Your LocalBusiness schema declares the same NAP that appears on every external source, creating a self-validating loop
- No orphaned or legacy listings exist — Old Yellow Pages entries from 2015 are deactivated. Marketing campaign directories from previous agencies are either updated or removed. Nothing contradicts your current information.
- Ongoing monitoring catches new conflicts before AI does — Regular audits identify when new auto-generated listings appear or when aggregators resync with outdated data
This isn't a one-time project. It's infrastructure.
The same way your practice has operational systems for patient scheduling, billing, and clinical documentation, a clean trust chain requires a management system that prevents citation drift over time.
Most practices don't have that system.
They react to problems after they're already invisible.
The practices winning AI recommendations are the ones that treat citation management as a core function of building Entity Trust — not an afterthought.
The Ongoing Management System
Citations decay.
Even if you clean everything up perfectly today — every aggregator updated, every directory accurate, every conflict resolved — drift will happen.
Aggregators resync with outdated data sources. New auto-generated listings appear. Directories you've never heard of scrape old information and republish it. Competitors submit incorrect information about your business (yes, that happens). Platforms change their data validation rules and flag previously clean listings as incomplete.
A citation profile that's flawless in January can have ten new conflicts by June if no one's monitoring it.
That's why ongoing management isn't optional.
It's the only way to maintain entity trust over time.
Here's what the system looks like:
Monthly citation audits across all three tiers (aggregators, platforms, industry directories).
Check for new listings that appeared. Verify existing listings haven't reverted to old data. Confirm recent updates propagated correctly.
Proactive aggregator submissions whenever business information changes.
Don't wait for conflicts to appear. Submit updates to Data Axle, Foursquare, and Neustar Localeze immediately so corrections flow downstream before AI engines pick up bad data.
Monitoring for auto-generated listings that scrape data from public sources or old directories.
When they appear, claim them and correct them before they feed conflicts into the AI validation system.
Duplicate suppression when multiple listings for the same business exist on one platform.
AI sees duplicates with slightly different information as entity conflicts. Consolidate them.
Schema markup synchronization on your website.
Every time NAP changes anywhere, schema gets updated to match. This keeps your website's self-declared identity aligned with external citations.
This is what separates AI-readable infrastructure from static web presence.
AI-readable infrastructure stays current. It adapts. It prevents drift before it becomes a trust failure.
And it's why Answer Engine Optimization isn't a one-time rebuild.
It's a compound growth system where every month of clean citation management builds on the last — deepening entity trust, strengthening validation signals, and widening the gap between you and competitors who treat this like a checkbox task.
How Long Until AI Notices
You fixed everything.
Submitted corrections to every aggregator. Updated every directory. Cleaned up legacy listings. Synchronized your schema.
How long before AI recommends you?
The honest answer: it depends on crawl cycles.
AI engines don't recrawl every source daily. They operate on schedules. Some sources get checked weekly. Some monthly. Some quarterly.
And AI's internal knowledge graph doesn't update the moment a single source corrects — it waits for consensus across multiple sources before rebuilding entity trust.
Here's the realistic timeline:
Weeks 1-2: Aggregator corrections are submitted and processing. Nothing visible yet.
Weeks 3-6: Corrections syndicate to downstream directories. AI engines begin encountering updated data on some platforms but not others. Partial improvement — not enough to shift recommendations yet.
Weeks 7-12: Critical mass. Enough sources now show clean data that AI's knowledge graph begins reflecting the corrections. Entity trust starts rebuilding. You may start appearing in AI recommendations inconsistently — sometimes your name, sometimes a competitor's, depending on which validation pathway the AI took.
Months 4-6: Full propagation. The vast majority of sources now show accurate data. AI's knowledge graph solidifies. Your entity trust is strong enough that you become the consistent recommendation when patients ask.
That's the best-case timeline — assuming you caught every conflict, submitted corrections to all the right places, and nothing unexpected broke during propagation.
Worst-case?
Add another three months if you missed a critical Tier 1 aggregator or if legacy listings keep resurfacing.
Search Engine Journal explains why Name, Address, Phone Number (NAP) consistency directly impacts how algorithms perceive and validate local entities — but the impact isn't immediate.
It's cumulative.
AI engines need to see the same clean data repeatedly across multiple crawl cycles before trust solidifies.
The practices that stay invisible are the ones that expect instant results.
They fix Google, see no change in two weeks, and assume it didn't work.
The practices that win are the ones that understand this is infrastructure work.
You're not flipping a switch. You're rebuilding a foundation. And foundations take time to settle before the structure above them becomes stable.
If you want to see where you stand right now — which sources have conflicts, how deep the trust damage is, and what the realistic recovery timeline looks like — run the AI Visibility Check.
It shows you exactly what AI engines are seeing when they evaluate your entity.
Frequently Asked Questions
What is considered a 'bad citation' for an AI engine?
A bad citation is any core business information that's incorrect, inconsistent, or outdated across online sources.
This includes obvious errors like wrong addresses or disconnected phone numbers. But it also includes subtle variations that humans wouldn't notice — slightly different business name formatting, mismatched service categories, conflicting hours of operation.
AI engines don't interpret context the way humans do.
They see data points that either align or conflict. "Dr. Smith Chiropractic" on one platform and "Smith Chiropractic Center" on another looks like two different entities to AI, even though you know they're the same business.
The standard isn't "close enough."
It's exact consistency across every source AI checks.
How do AI engines like ChatGPT and Gemini find business citations?
AI engines crawl vast networks of sources to build consensus about business identity.
They start with your website and schema markup. Then they check major platforms like Google Business Profile, Apple Maps, and Bing Places. Then they validate against Tier 1 data aggregators like Data Axle, Foursquare, and Neustar Localeze.
From there, they scan industry-specific directories relevant to your market — Healthgrades, Zocdoc, Vitals for healthcare providers. Local directories. Chamber of commerce listings. Professional association databases.
They're not checking one or two sources.
They're checking dozens.
And they're looking for alignment. When the same information appears consistently across multiple independent sources, AI builds confidence that the data is accurate and the entity is legitimate.
When conflicts exist, AI downgrades trust or removes you from consideration entirely.
Can't I just fix the incorrect information on my own website?
Your website is critical.
But it's not enough.
AI engines don't take your website's word for what your business information is. They verify your claims against third-party sources.
Think of it like this: your website is your self-declared identity. Citations are third-party validation.
AI trusts third-party validation more than self-declaration because it's harder to manipulate.
If your website says your address is 123 Main Street but Data Axle says it's 456 Oak Avenue, AI sees a conflict.
And the conflict weakens trust in both sources.
You need your website and external citations to align.
One without the other doesn't build entity trust — it creates the exact kind of data conflict AI engines interpret as a credibility failure.
What's the difference between a citation for Google Search and for an AI Answer Engine?
For traditional search, citations influenced rankings in a list.
Google would use citation data to help determine your position in the local map pack. Clean citations might move you from position five to position three. Messy citations might drop you to position seven.
Either way, you were still in the results. Patients could still find you if they scrolled.
For AI answer engines, citations determine credibility for a singular recommendation.
AI isn't building a ranked list. It's making a verdict.
When someone asks ChatGPT or Gemini who the best chiropractor in their area is, the AI either says your name or it doesn't.
There's no second page. No "scroll for more options."
You're either the answer or you're invisible.
Citations in the AI era aren't about ranking higher. They're about being recognized as a legitimate, trustworthy entity at all.
The stakes shifted from "where do I appear in the list" to "does AI believe I exist."
That's the difference.
And it's why citation management strategies built for traditional SEO don't work for AI authority.
How long does it take for a corrected citation to fix the damage?
Submitting the correction is the first step.
Getting it to propagate through AI's knowledge graph takes weeks or months.
Data aggregators don't update in real time. They process corrections on schedules — some monthly, some quarterly.
Once the aggregator updates, the correction has to syndicate to downstream directories. Then AI engines have to recrawl those directories to pick up the change.
Even in the best case, you're looking at 6-12 weeks from correction submission to AI engines reflecting the updated data.
More realistically, 3-6 months for full propagation across the entire citation ecosystem.
And that's assuming you only had one bad citation.
If you have conflicts across ten sources, and each operates on a different update schedule, the timeline extends because corrections are rolling in at different speeds.
This is why ongoing citation management is more effective than reactive cleanup.
Preventing conflicts is faster than fixing them after they've already broken entity trust.
What are the most important citations to get right for building Entity Trust?
Core data aggregators are the foundation.
Data Axle, Foursquare, Neustar Localeze, Factual — these are Tier 1 sources that syndicate your information to hundreds of downstream directories.
Getting these right corrects the root of the problem and prevents cascading conflicts across the entire ecosystem.
After aggregators, focus on primary search platforms.
Google Business Profile, Apple Maps, Bing Places — these are high-visibility, high-authority sources AI engines check constantly.
Clean data here delivers the fastest trust signal improvements.
Then layer in industry-specific directories.
For chiropractors: Healthgrades, Zocdoc, Vitals, WebMD. These serve as niche validators that reinforce your authority in healthcare.
AI engines weight domain-relevant sources more heavily when making recommendations in specific industries.
The hierarchy matters.
Fix Tier 1 first. Then Tier 2. Then Tier 3.
If you try to fix individual directories without addressing the aggregators feeding them bad data, you're fighting a losing battle — the conflicts will just resurface when aggregators resync.
Conclusion
Fixing the fragile trust chain isn't optional maintenance.
It's foundational security.
Every month your citations remain inconsistent, AI engines are running validation checks and choosing not to recommend you.
That gap doesn't close on its own. It widens as competitors who understand this build cleaner, more trusted entity profiles.
The practices winning AI recommendations six months from now are the ones fixing their trust chains today.
Not because they got lucky.
Because they recognized that authority isn't built on a beautiful website or clever content alone — it's built on the invisible infrastructure AI engines use to determine whose name gets said.
One bad citation breaks the entire chain.
One clean, systematically managed citation profile compounds trust every month it stays accurate.
The question isn't whether this matters.
The question is whether you're willing to address it before your competitors do.
Want to know which citations are currently breaking your entity trust — and what the realistic timeline looks like to fix them? The AI Visibility Check shows you exactly what ChatGPT, Gemini, and Grok are seeing when they validate your practice. It takes 15 minutes and makes the next conversation a lot more concrete.
621 Enterprises, Inc. | Copyright 2026 | All rights reserved