
Why Generic AI Prompts Make Your Chiropractic Content Invisible
The problem isn't that AI wrote the content. The problem is that generic prompts optimize for human readability, not machine trust. They produce content that looks fine to a person scrolling your website but is structurally invisible to the systems deciding whose name gets said when someone asks, "Who's the best chiropractor near me?"
Here's what's actually happening. Answer engines don't rank content anymore. They cite it. Or they don't. And the decision to cite comes down to whether the content demonstrates entity trust, semantic density, verifiable claims, and clear expertise signals. A generic AI prompt cannot engineer any of those elements because it doesn't know they exist. It's optimizing for a game that ended two years ago.
Let's be clear: there's a huge gap between "content that exists" and "content that AI actually recommends." We're going to break down exactly why your AI articles fall into the first bucket—and what it takes to get into the second.
Last Updated: April 27, 2026
- • The Brutal Reality: AI Content That Nobody Sees
- • What Generic AI Prompts Actually Produce
- • The Machine Trust Problem: Why AI Engines Ignore Your Content
- • Entity Trust: The Invisible Foundation Generic Prompts Can't Build
- • Semantic Density vs. Keyword Stuffing
- • The Validation Gap: Single-AI Output Is Structurally Unreliable
- • Why "Better Prompts" Won't Fix the Problem
- • What AEO Content Actually Requires
- • FAQ
- • Can't I just use a more detailed AI prompt to get better results?
- • What is "Entity Trust" and why does it matter for AI content?
- • Does Google penalize AI-generated content?
- • What's the difference between content for a Google list and content for an AI answer?
- • How is Answer Engine Optimization (AEO) different from the SEO I'm already doing?
- • The First Step: See What AI Actually Says About Your Practice
The Brutal Reality: AI Content That Nobody Sees

You published ten articles last month. AI wrote every one. You followed the advice—"just use a really detailed prompt." The content reads fine. It covers the topics. It's even formatted with headings and bullet points.
And nobody called.
Here's what most chiropractors don't realize: the content marketing industry sold you a solution to a problem that no longer exists. "Write more blog posts" worked when Google showed ten blue links and patients clicked through to read. That chain is broken. Patients don't click anymore. They ask AI engines for a recommendation—and those engines either say your name or they don't.
They don't say your name. You don't exist. Same outcome.
The "Content Exists" Trap
Creating content and being visible are not the same thing.
You have articles. They're indexed. They show up in your site search. A person could read them if they found them. But AI engines aren't readers—they're validators. And when they scan your content, they're not asking "does this make sense to a human?" They're asking: "Is this entity trustworthy? Are these claims verifiable? Does this practice demonstrate clear expertise signals I can stake my recommendation on?"
The answer is no. Which means the content gets ignored. Every time.
| What You Created | What AI Engines See | What Happens |
|---|---|---|
| 10 blog posts on common chiropractic topics | Text without entity verification, no schema markup, generic claims without source citations | Content exists but is never cited—zero patient calls |
| Well-formatted articles with headings and keywords | Prose optimized for human skimming, not machine-readable trust signals | AI engines pass over your practice and recommend competitors with building entity trust |
| AI-generated content published weekly | Single-pass output with factual inconsistencies, no validation layer, weak semantic density | Content that looks authoritative to humans but fails every trust filter AI uses to decide who to cite |
Here's the kicker: invisible means the same thing as nonexistent in a zero-click world where being the single recommended answer is the only outcome that generates patient calls.
Why This Affects Chiropractors Differently
Local health intent is binary.
When someone asks ChatGPT or Perplexity "who's the best chiropractor near me," they don't get ten options. They get one or two names. If you're not one of them, the patient never knows you exist—no matter how good your website looks or how many blog posts you published.
This isn't like traditional search where ranking fifth still gets you a few clicks. In zero-click environments, second place is the same as invisible. And every month you operate without the authority infrastructure competitors are building, that gap compounds.
The content you published isn't bad. It's just invisible. And invisible doesn't book appointments.
What Generic AI Prompts Actually Produce
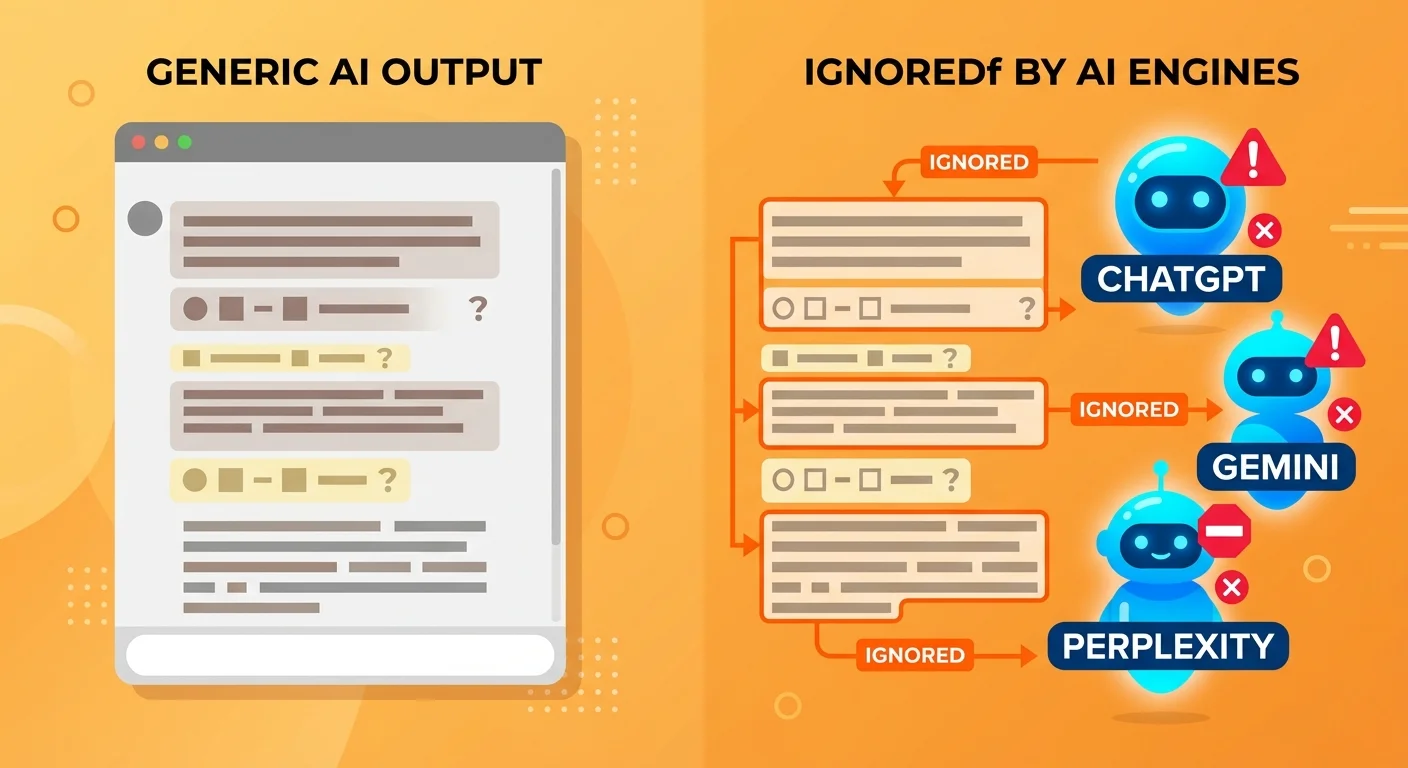
A generic prompt produces text. That's it.
You get paragraphs that explain a topic. Maybe some formatting. Maybe even a conversational tone. What you don't get is the technical structure AI engines require to validate that text as trustworthy, authoritative, and worth citing.
Think of it this way: the prose is the paint. The infrastructure is the frame, the canvas, and the wall it hangs on. Generic prompts give you paint with nowhere to put it—and AI engines don't cite floating paint.
Prose Without Infrastructure
Here's what generic AI content is missing at the technical level:
- Schema markup — the structured data that tells AI engines what kind of entity you are, where you're located, and what services you offer
- Entity anchors — the consistent NAP (name, address, phone) across your website, Google Business Profile, and third-party directories that prove you're a real, verifiable business
- Semantic clustering — the depth of related concept coverage that signals comprehensive expertise, not surface-level keyword targeting
- Citation-worthy structure — the verifiable claims, sourced statistics, and institutional links that give AI engines confidence your content is factually accurate
A prompt can't build any of that. It can tell ChatGPT to "write 1,500 words on sciatica treatment," but it can't engineer the trust signals that make AI engines willing to stake their reputation on recommending your practice.
Google's Search Quality Rater Guidelines make this explicit: content quality is judged by Experience, Expertise, Authoritativeness, and Trust (E-E-A-T). Generic AI prompts can't fabricate those signals—they can only produce text that claims them.
Sound fair? Let's keep going.
The Hallucination Layer
Every AI model hallucinates. That's not a bug—it's how large language models work. They predict the next most likely word based on training data, not by verifying facts in real time.
When you use a single AI tool with a generic prompt, you're publishing unvalidated output. The prose might sound confident. The statistics might look real. But unless you're manually fact-checking every claim—which most practices aren't—you're rolling the dice on factual accuracy.
And AI engines know this. They don't trust single-pass AI content because they know it's structurally unreliable. Research from Cornell University confirms what answer engines already assume: AI-generated text frequently contains factual inconsistencies, invented sources, and fabricated data points.
That's why validation matters. Not because you want better content—because AI engines won't cite content they can't verify.
Human-Readable vs. Machine-Readable
Content optimized for human skimming is not the same as content optimized for AI citation.
Humans look for headers, bullet points, and readability. AI engines look for schema markup, entity consistency, verifiable claims, and semantic depth. If your content only addresses the human layer, you're invisible to the systems deciding whose name gets recommended.
Those aren't variations of the same thing.
The Machine Trust Problem: Why AI Engines Ignore Your Content

AI engines don't cite content they can't trust.
That's the filter every piece of content passes through before it becomes a recommendation. And "trust" in this context isn't subjective—it's technical. It's the presence or absence of verifiable entity signals, consistent data across platforms, institutional sources backing up claims, and structured markup that proves you are who you say you are.
Generic AI content fails that filter by default because it was never designed to pass it.
Why Answer Engines Default to Silence
Recommending an unverified source is a liability.
When ChatGPT or Gemini says "you should see Dr. Smith," they're staking their credibility on that recommendation. If Dr. Smith turns out to be unlicensed, or their clinic doesn't exist, or the information is outdated—that's a trust hit the AI engine takes.
So the default behavior is conservative: when entity trust is weak or missing, the engine doesn't recommend anyone. No citation is safer than a bad citation. And in local health markets where dozens of chiropractors exist, AI engines have no shortage of alternatives with stronger trust signals to choose from.
Google's official stance makes this clear: high-quality, people-first content is the goal, regardless of how it's produced. But low-quality AI content—the kind that lacks verification, entity trust, and structural clarity—is still treated as spam.
Why "SEO Best Practices" Don't Apply Anymore
Traditional SEO was built for a world where ranking on page one mattered.
You optimized for keywords. You built backlinks. You tracked positions. The goal was to be one of ten results—and if you hit spots 1-3, you got the majority of the traffic.
That game is over. Not because SEO died—because the outcome changed. AI search doesn't produce ten results. It produces a verdict. And optimizing to be "one of ten" when the player only gets one answer is the wrong strategy entirely.
Generic prompts still follow outdated SEO frameworks because that's what they were trained on. They focus on keyword density, readability scores, and content length—all metrics designed for ranking in a list. None of that matters when the question is "who should I trust?" instead of "who mentions this keyword most?"
That's why traditional SEO for chiropractors is structurally obsolete. The optimization target moved—and generic AI prompts are still aiming at the old one.
Entity Trust: The Invisible Foundation Generic Prompts Can't Build
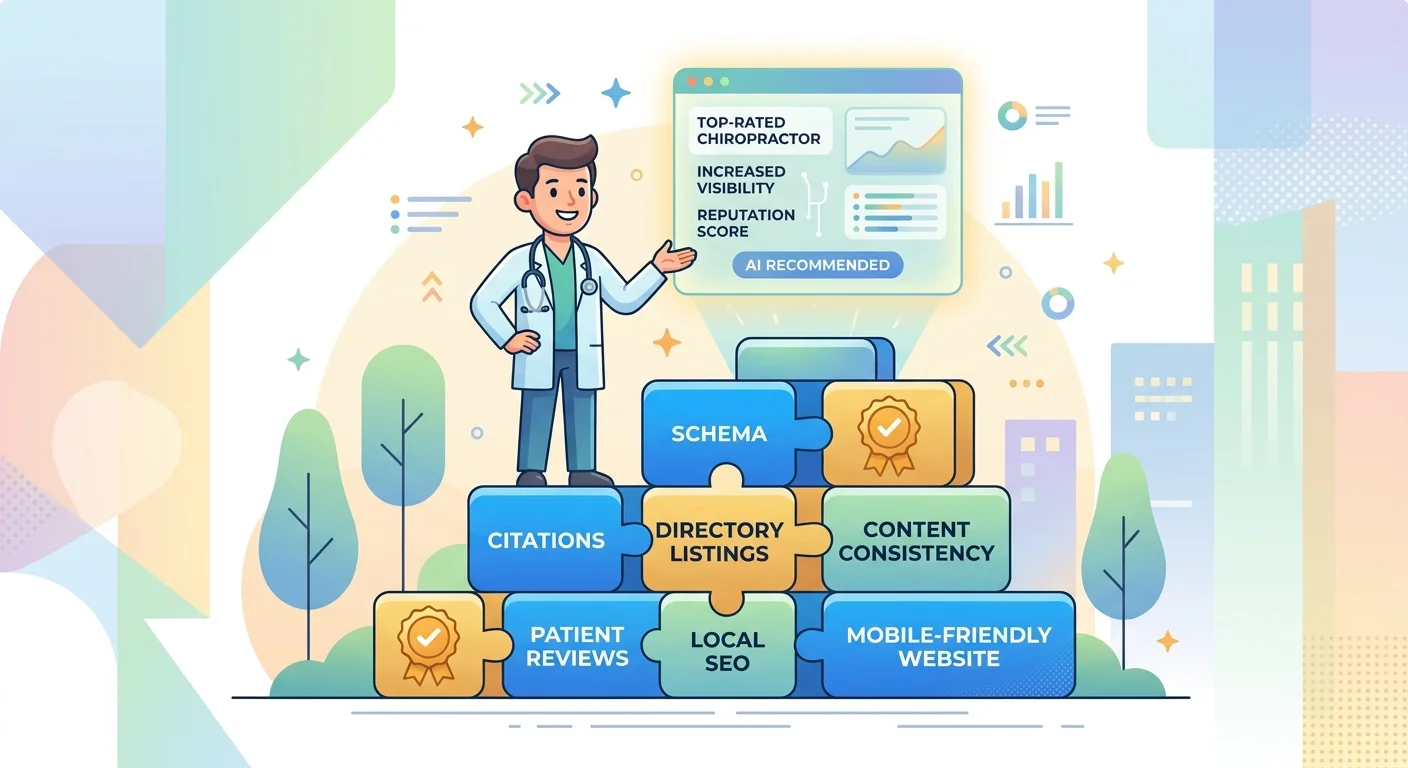
Entity trust is AI's confidence that your practice is real, legitimate, and authoritative enough to recommend.
It's not built from content alone. It's built from consistent, verifiable information across every platform AI engines check—your website, your Google Business Profile, third-party directories like Healthgrades and Zocdoc, and the structured data tying all of it together.
A generic prompt can't touch any of that. It can write a blog post. It can't sync your NAP across platforms, add schema markup to your site, or build the knowledge graph connections that prove you're a trusted entity.
How AI Validates Entity Claims
When an AI engine evaluates whether to cite your practice, it's running cross-platform verification.
It checks:
- Schema markup — Does your website include LocalBusiness schema with your name, address, phone, and service offerings clearly structured?
- Directory consistency — Do Healthgrades, Vitals, and WebMD all show the same information, or are there conflicting addresses and phone numbers?
- Knowledge graph presence — Is your practice represented in Google's Knowledge Graph, with connections to your location, specialty, and related entities?
- Citation patterns — Are other authoritative sites (local news, health directories, professional associations) linking to or mentioning your practice?
If any of these validation points fail, the engine downgrades your trust score. And generic AI content—no matter how well-written—can't fix infrastructure problems.
| Entity Trust Signal | What AI Checks | Generic Prompt Capability | Required System |
|---|---|---|---|
| Schema Markup | Structured data declaring entity type, location, services | Cannot add code to website | Developer implementation or CMS schema plugin |
| NAP Consistency | Name, address, phone match across website, GBP, directories | Cannot edit third-party listings | Manual directory management or listing sync tool |
| Knowledge Graph Integration | Practice appears in Google's entity database with verified connections | Cannot create or influence knowledge graph entries | Long-term entity building through citations, structured data, and directory presence |
| Citation Velocity | Frequency and authority of external sites mentioning the practice | Cannot generate real external backlinks or mentions | PR, partnerships, guest posts, institutional affiliations |
Now... this part matters.
What Generic Prompts Miss Entirely
A prompt is an instruction to a text generator. It is not a command to an infrastructure builder.
You can ask ChatGPT to "write an article that builds entity trust," and it will produce prose that talks about trust. But it won't build your Google Business Profile. It won't add LocalBusiness schema to your homepage. It won't sync your NAP across directories or create the structural foundation AI engines require to validate your entity.
That's not a failure of the tool. It's a misunderstanding of what the tool does. Generic prompts optimize for text output. Authority infrastructure is the foundation those prompts assume already exists.
Semantic Density vs. Keyword Stuffing
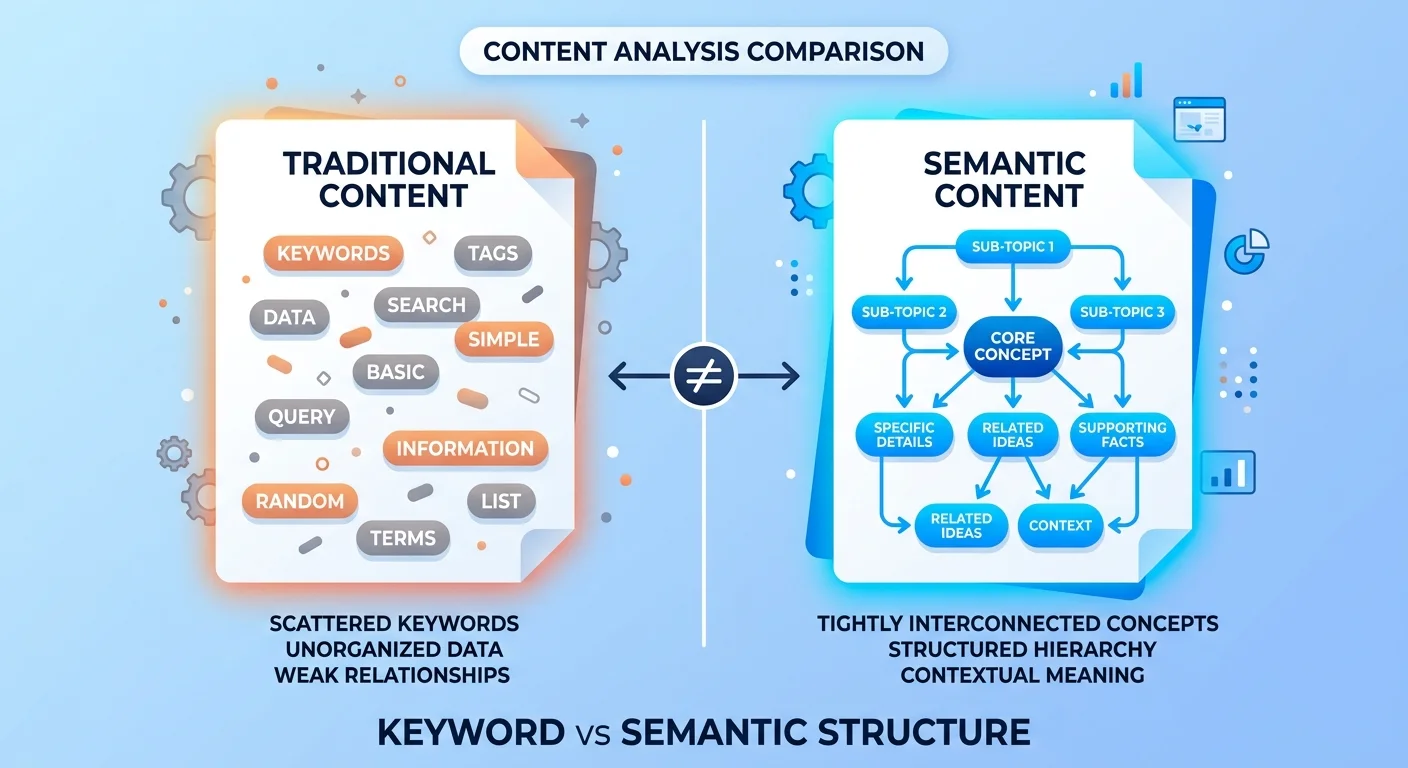
AI engines don't count keywords. They map concepts.
Semantic search is the technical term for how modern answer engines understand content. They're not looking for how many times you said "chiropractic adjustment"—they're evaluating whether your content covers the full semantic field of related concepts, sub-topics, and intent layers that signal comprehensive expertise.
Generic prompts default to keyword optimization because that's what they were trained on. But keyword frequency is a ranking signal from 2015. It's not a trust signal in 2026.
Why AI Engines Prioritize Depth Over Keywords
When someone asks "should I see a chiropractor for lower back pain," AI engines need to know you understand:
- The biomechanics of lower back pain (direct intent)
- When chiropractic care is appropriate vs. when medical imaging or surgery is needed (counter-intent)
- What a first appointment looks like and what outcomes are realistic (post-intent)
- How spinal manipulation differs from physical therapy or massage (latent intent)
- Why some patients don't respond to adjustments and what alternative approaches exist (indirect intent)
That's semantic density. That's the depth of concept coverage that tells AI engines "this practice understands the full landscape of this patient's question—not just the surface-level answer."
Generic prompts produce surface-level coverage because they optimize for readability and length, not intent mapping. They touch the topic. They don't cover its full semantic field.
The Generic Prompt Default: Surface-Level Coverage
Here's what happens when you use a generic prompt:
You get an intro paragraph that explains the problem.
You get a section on what chiropractic adjustments are.
You get a conclusion that says "contact us to schedule an appointment."
What you don't get is the five-layer intent coverage that AI engines use to determine whether your content is authoritative enough to cite. You don't get the counter-intent section addressing why chiropractic care might not be the right fit for certain conditions. You don't get the latent intent exploration of related factors like posture, ergonomics, or exercise protocols that influence long-term outcomes.
And without that depth, your content is categorized as "thin"—even if it's 1,500 words long.
Here's the kicker: length doesn't equal depth. AI engines see right through it.
The Validation Gap: Single-AI Output Is Structurally Unreliable
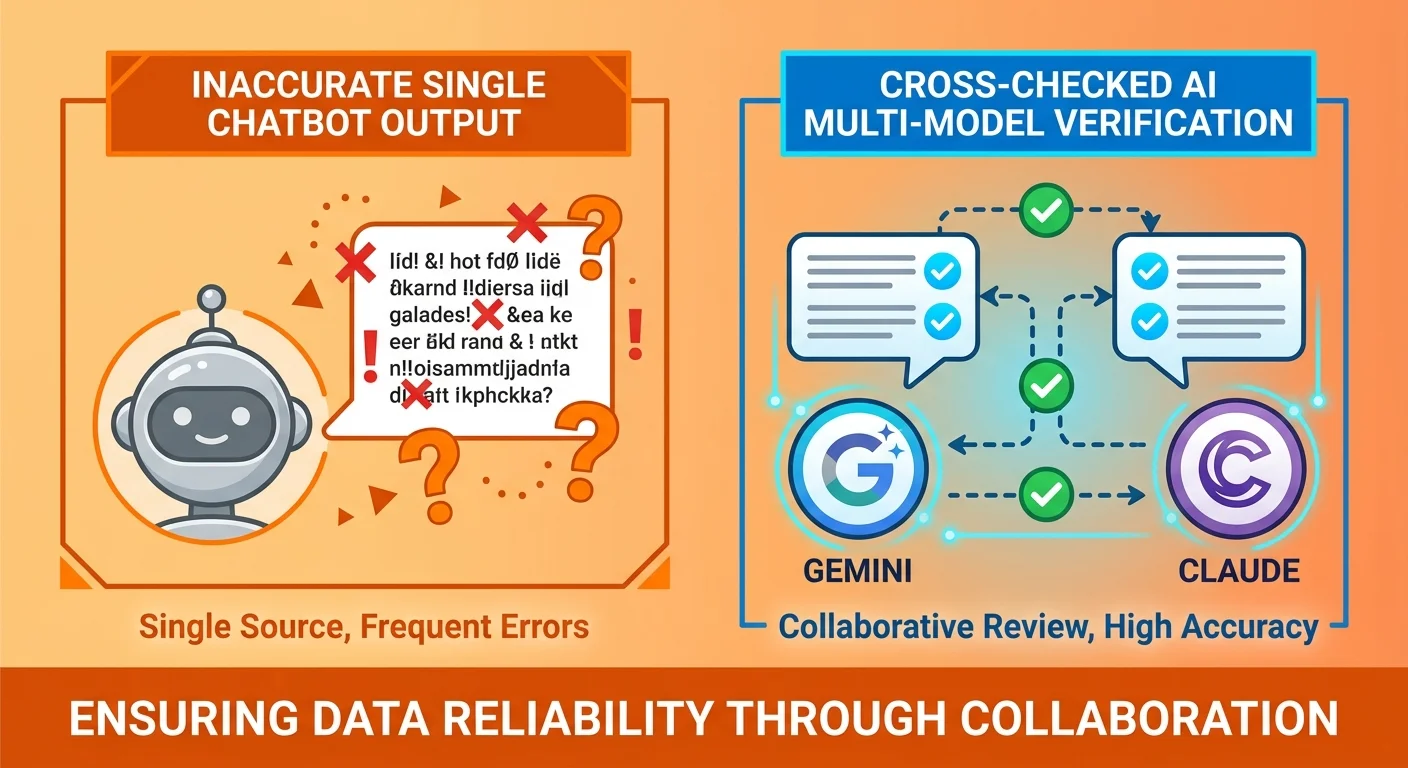
Every AI model hallucinates. This is not a flaw in a specific tool—it's how large language models work.
When you use a single AI with a generic prompt, you're publishing unvalidated output. The statistics might be invented. The claims might be unsourced. The "expert advice" might be a confident-sounding fabrication. And unless you're manually fact-checking every sentence—which most practices aren't—you're rolling the dice on accuracy.
AI engines know this. That's why they don't trust single-pass AI content by default.
This Is Not for the DIY Underestimator
Quick pause before we go further.
If you believe a more detailed prompt is the only missing piece—if you think the solution to invisible content is "just add more instructions to ChatGPT"—you're misunderstanding the game entirely.
The system isn't "prompt → publish." It's research → draft → validate → refine → publish with infrastructure. And infrastructure includes entity trust, schema markup, directory consistency, citation velocity, and semantic density—none of which a prompt can build.
If you're looking for a way to replicate professional-grade AEO content with a better prompt and fifteen minutes on ChatGPT, this isn't the article for you. No hard feelings. But if you're tired of publishing content that produces zero patient calls because it lacks the structural foundation AI engines require to trust it—keep reading.
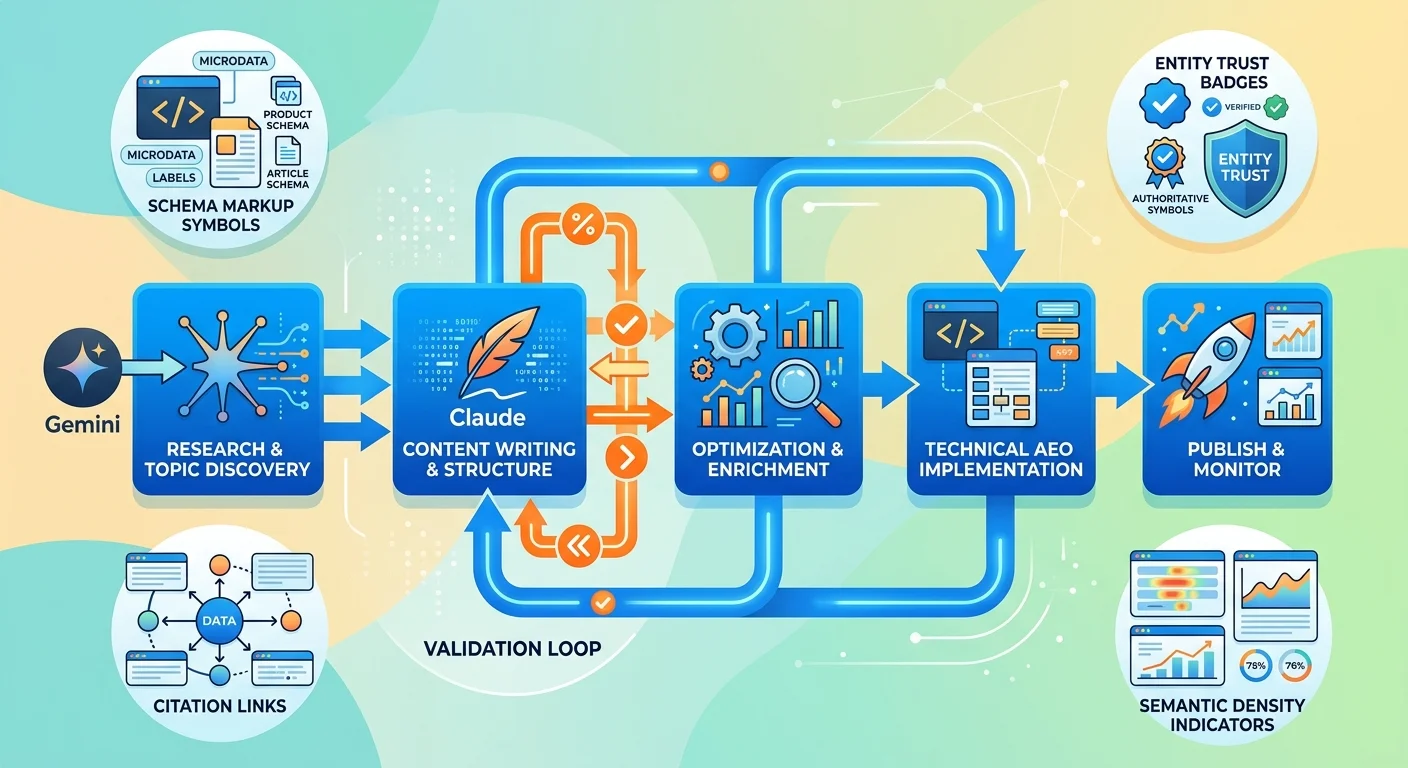
How the Two-AI Validation System Works
We don't publish vibes. We publish receipts.
That's not a tagline—it's the operational standard. Every statistic sourced. Every claim verified. Two AI tools cross-checking each other's work.
Here's the process:
- Gemini researches and validates — pulls institutional sources, verifies claims, maps semantic clusters, identifies factual anchors
- Claude writes — produces the prose using Gemini's verified research as the foundation
- Gemini re-validates — checks Claude's output for hallucinations, unsourced claims, and factual drift
- Claude refines — corrects any flagged issues and tightens the final output
It's not faster than a generic prompt. It's not cheaper. But it produces content AI engines can verify—and verification is the filter that determines whether you get cited or ignored.
The two-AI validation system exists because single-pass output is structurally unreliable. Not sometimes. Always. And AI engines treat it accordingly.
HubSpot's 2024 State of SEO research confirms what I've seen firsthand: the shift to AI-driven search prioritizes topic authority and factual accuracy over traditional keyword targeting. Practices that publish validated, citation-worthy content are compounding authority. Practices that publish generic AI output are compounding invisibility.
Why "Better Prompts" Won't Fix the Problem

A prompt is an instruction to a text generator. It is not a command to an infrastructure builder.
That's the line most chiropractors miss. They assume the problem is the quality of the input—that if they just craft a more detailed, more specific, more "perfect" prompt, the output will suddenly become citation-worthy.
It won't. Because the text was never the bottleneck.
The 5% vs. 95% Misunderstanding
The prompt determines maybe 5% of what makes content visible to AI engines.
The other 95% is:
- Entity trust — is your practice verified across platforms with consistent NAP data and knowledge graph presence?
- Schema markup — does your site include structured data AI engines can parse?
- Validation — has every claim been fact-checked and sourced to institutional references?
- Semantic structure — does the content cover the full five-layer intent landscape, or just the direct question?
- Citation-worthy architecture — is the content formatted and linked in a way that AI engines recognize as authoritative?
You can spend an hour perfecting your ChatGPT prompt. If those five elements aren't in place, the content is still invisible.
That's not a failure of the tool. It's a misunderstanding of what the tool was designed to do. Generic AI tools optimize for prose quality. They assume the infrastructure already exists. When it doesn't, the output has nowhere to go.
What You're Actually Optimizing For
If your prompt optimizes for "write better text," you're solving the wrong problem.
The goal isn't readable prose. The goal is machine-trustable content that AI engines feel confident citing. Those are not the same thing.
Human-readable content can fail every trust filter AI engines use and still look great to a person skimming your site. Machine-trustable content might not win any prose awards, but it passes the validation checks that determine whether your practice gets recommended or ignored.
| Element | Controlled by Prompt? | Controlled by System? |
|---|---|---|
| Prose quality and readability | Yes | No |
| Schema markup and structured data | No | Yes |
| Entity trust and NAP consistency | No | Yes |
| Fact-checking and source verification | No | Yes |
| Five-layer intent coverage | Partially (with detailed instruction) | Yes (engineered into research process) |
| Semantic density and concept mapping | Partially (if prompt is highly specific) | Yes (validated against topic clusters) |
| Citation-worthy formatting | No (output follows default structure) | Yes (designed for AI engine parsing) |
A better prompt improves the first row. It does nothing for the rest.
Alright, quick reality check: you can keep refining prompts, or you can start building what AI engines actually need to see before they'll say your name. Your call.
What AEO Content Actually Requires
Answer Engine Optimization is not "SEO with AI tools." It's a different discipline with a different outcome.
Traditional SEO optimized for ranking in a list. AEO optimizes for being the singular, trusted answer. And the technical requirements to achieve that outcome are not incremental improvements on old methods—they're a complete rebuild of how content is researched, validated, structured, and integrated with entity infrastructure.
AEO Content Writing is not "blog posts with better prompts." It's engineered content designed to pass the trust filters answer engines use to decide who gets cited. And those filters require three distinct layers working in concert.
The Infrastructure Layer
This is the foundation everything else builds on. Without it, even perfect content is invisible.
- Schema markup — LocalBusiness, MedicalBusiness, or HealthAndBeautyBusiness schema embedded on your site with accurate name, address, phone, services, and review aggregates
- Knowledge graph connections — your practice exists in Google's entity database with verified links to your location, specialty, and related health topics
- NAP consistency — your name, address, and phone number match exactly across your website, Google Business Profile, Healthgrades, Vitals, Zocdoc, and every other directory listing
- Directory presence — active, claimed, and optimized profiles on the platforms AI engines check to validate local health entities
Generic prompts can't build any of this. This is technical infrastructure work that happens outside of content creation entirely. But without it, the content has no entity to attach to—and AI engines don't cite floating content.
The Validation Layer
This is where single-AI output fails by default.
Every claim needs a source. Every statistic needs verification. Every "expert recommendation" needs institutional backing. Not because humans demand it—because AI engines won't cite content they can't validate.
The validation layer includes:
- Fact-checking — every claim cross-referenced against institutional sources (NIH, CDC, peer-reviewed journals)
- Source verification — every statistic traced to its original publication, not secondary blog citations
- Claim substantiation — every recommendation backed by clinical evidence or professional guidelines
- Dual-AI cross-check — Gemini validates what Claude wrote, flagging hallucinations and unsourced assertions before publication
This is not a one-time pass. It's a built-in step in the content production process. And it's why validated AEO content takes longer to produce than generic AI output—because verification is the entire point.
BrightEdge's research on zero-click search shows that over 50% of searches now end without a click. That means the citation is the entire outcome. If AI engines don't trust your content enough to cite it, you're not just losing traffic—you're losing the patient entirely.
The Intent Layer
This is what separates surface-level content from citation-worthy depth.
AI engines don't just evaluate whether you answered the question. They evaluate whether you addressed the full landscape of intent behind the question. That includes:
- Direct intent — the literal question asked
- Indirect intent — the real goal behind the question (not just "what is sciatica treatment" but "will this fix my problem and how long will it take")
- Latent intent — related considerations the patient doesn't know to ask about (posture, ergonomics, exercise protocols, when imaging is necessary)
- Counter-intent — why chiropractic care might not be the right fit for this condition (when surgery is indicated, when physical therapy is more appropriate, contraindications)
- Post-intent — what happens after the answer (what a first appointment looks like, realistic timelines, cost considerations, insurance coverage)
Generic prompts default to direct intent only. They answer the literal question and stop. That's thin content by AI engine standards—even if it's 1,500 words long.
Five-layer intent coverage is what creates semantic density. And semantic density is what signals comprehensive expertise to AI engines deciding who to trust.
FAQ
Can't I just use a more detailed AI prompt to get better results?
A more detailed prompt produces better prose. It does not produce the entity trust, schema markup, validation, or semantic structure AI engines require to cite your content.
The prompt is maybe 5% of what determines AI visibility. The other 95% is infrastructure—entity verification, structured data, fact-checking, intent mapping, and citation-worthy formatting. Those elements exist outside the prompt entirely.
You can spend an hour perfecting your ChatGPT instructions. If your practice lacks entity trust and your content lacks validation, the output is still invisible to answer engines. That's not a failure of the tool—it's a misunderstanding of what the tool was designed to do.
What is "Entity Trust" and why does it matter for AI content?
Entity trust is AI's confidence that your practice is real, legitimate, and authoritative enough to recommend.
It's built from consistent, verifiable information across every platform AI engines check—your website, Google Business Profile, third-party directories like Healthgrades and Zocdoc, and the structured data tying it all together. When AI engines evaluate whether to cite your practice, they're cross-referencing your name, address, phone, services, and reviews across multiple sources.
If any of those data points conflict—or if key platforms are missing entirely—the engine downgrades your trust score. And low entity trust means your content doesn't get cited, no matter how well-written it is.
Generic AI prompts can't build entity trust. They can produce text that claims authority, but they can't sync your NAP across directories, add schema markup to your site, or create the structural foundation AI engines use to validate your entity.
Does Google penalize AI-generated content?
Google penalizes low-quality content, regardless of its origin.
Their official guidance is clear: high-quality, people-first content is the goal, whether it's written by a human or produced by AI. The issue isn't that AI wrote it—it's that most AI-generated content is thin, unverified, and lacks the expertise signals that separate authoritative sources from content mill spam.
Generic AI output typically fails quality standards because it's optimized for readability, not trust. It lacks sourced claims, validated statistics, entity verification, and the structural depth AI engines use to determine whether content is citation-worthy.
Validated AEO content—where every claim is fact-checked, every statistic sourced, and the content is engineered to pass trust filters—doesn't get penalized. It gets cited. Because the origin doesn't matter. The verification layer does.
What's the difference between content for a Google list and content for an AI answer?
Content for a list aims to rank. Content for an answer aims to be cited.
In traditional search, the goal was to be one of ten results on page one. If you hit positions 1-3, you got the majority of the traffic. Content optimized for that outcome focused on keywords, backlinks, and technical SEO signals that helped Google place you in the list.
AI search doesn't produce a list. It produces a verdict. When someone asks ChatGPT or Perplexity "who's the best chiropractor near me," they get one or two names—not ten options to click through and evaluate.
That changes what content needs to do. Instead of "mention this keyword enough times to rank," the requirement is "demonstrate enough trust, depth, and verifiable expertise that AI engines feel confident staking their reputation on recommending you."
Those are not the same optimization targets. And generic AI prompts are still aiming at the old one.
How is Answer Engine Optimization (AEO) different from the SEO I'm already doing?
Traditional SEO optimizes for a list. AEO optimizes for trust.
The technical requirements are different. SEO focused on keyword targeting, backlink profiles, and on-page factors that influenced where Google ranked you in a list of results. AEO focuses on entity trust, schema markup, content validation, semantic density, and the structural signals AI engines use to determine who is authoritative enough to cite.
The outcome is different. SEO success meant ranking on page one and getting click-through traffic. AEO success means being the singular recommended answer—no clicks required, because the patient gets your name directly in the AI response.
And the competitive landscape is different. In traditional search, dozens of practices could coexist on page one. In AI search, there's one answer. If you're not it, you're invisible. That's not hyperbole—it's the structural reality of zero-click environments where being cited is the only outcome that generates patient awareness.
The First Step: See What AI Actually Says About Your Practice
There's no version of this where doing nothing is a safe play.
AI is already making recommendations in your market. Either your name is in the answer or a competitor's is. That gap widens every month it goes unaddressed.
The AI Visibility Check takes 15 minutes. It'll show you exactly where you stand. If the results don't make the problem self-evident — walk away. No pressure. But if they do? You'll know exactly what to do next.
621 Enterprises, Inc. | Copyright 2026 | All rights reserved