
The Machine-Verifiable Human: Protecting Your Founder Identity from AI Hallucinations
A machine-verifiable human is a person whose identity, credentials, and expertise are structured with semantic markup so AI models can parse, validate, and trust them. This is not about social media profiles or professional biographies written for human readers. It is about implementing technical infrastructure that allows AI answer engines like ChatGPT, Gemini, and Perplexity to understand who you are, verify your claims, and connect you to your business as an authority figure without fabricating details or substituting your name with someone else's.
Protecting your founder identity from AI hallucinations requires establishing a canonical source of truth for your personal entity. This means creating a dedicated page on your website that functions as your digital identity anchor, implementing Person schema markup to define your factual attributes in machine-readable format, and linking this canonical source to verified third-party profiles across the web. Together, these elements create a redundant, cross-verified digital footprint that AI engines can reference when they encounter your name in any context.
The risk is immediate and documented. AI engines have fabricated incorrect founder names for real businesses, invented credentials that do not exist, and attributed work to the wrong individuals. When someone asks an AI engine about your expertise or your business, the answer may include your competitor's name instead of yours, a fabricated professional history, or claims you never made. Once an AI engine associates incorrect information with your identity, that misinformation can propagate across multiple platforms and become the default answer for thousands of queries. The machine-verifiable human framework addresses this vulnerability by giving AI engines a structured, authoritative reference point they can trust.
This is not theoretical. It is operational. The question is not whether AI will hallucinate details about founders in your industry. The question is whether your identity infrastructure is strong enough to prevent it.
Last Updated: May 5, 2026
- • Why AI Fabricates Founder Identities
- • The Michael Walen Problem: A Real Example
- • What Makes a Human Machine-Verifiable
- • The Three Technical Layers of Founder Identity Protection
- • How to Build Your Canonical Identity Page
- • Person Schema: The Technical Infrastructure AI Reads
- • Linking Your Entity to the Knowledge Graph
- • Common Mistakes That Invite AI Hallucinations
- • Why a LinkedIn Profile Is Not Enough
- • FAQ
- • What is the difference between a brand entity and a person entity?
- • Can AI just learn who I am from my website's about page?
- • How does having a "machine-verifiable" identity help my business?
- • What is the first step to building my personal knowledge graph?
- • Is it possible to completely prevent AI hallucinations about me?
- • Do I need to hire a developer to implement Person schema?
- • How long does it take for AI engines to recognize my verified identity?
- • Conclusion
Why AI Fabricates Founder Identities
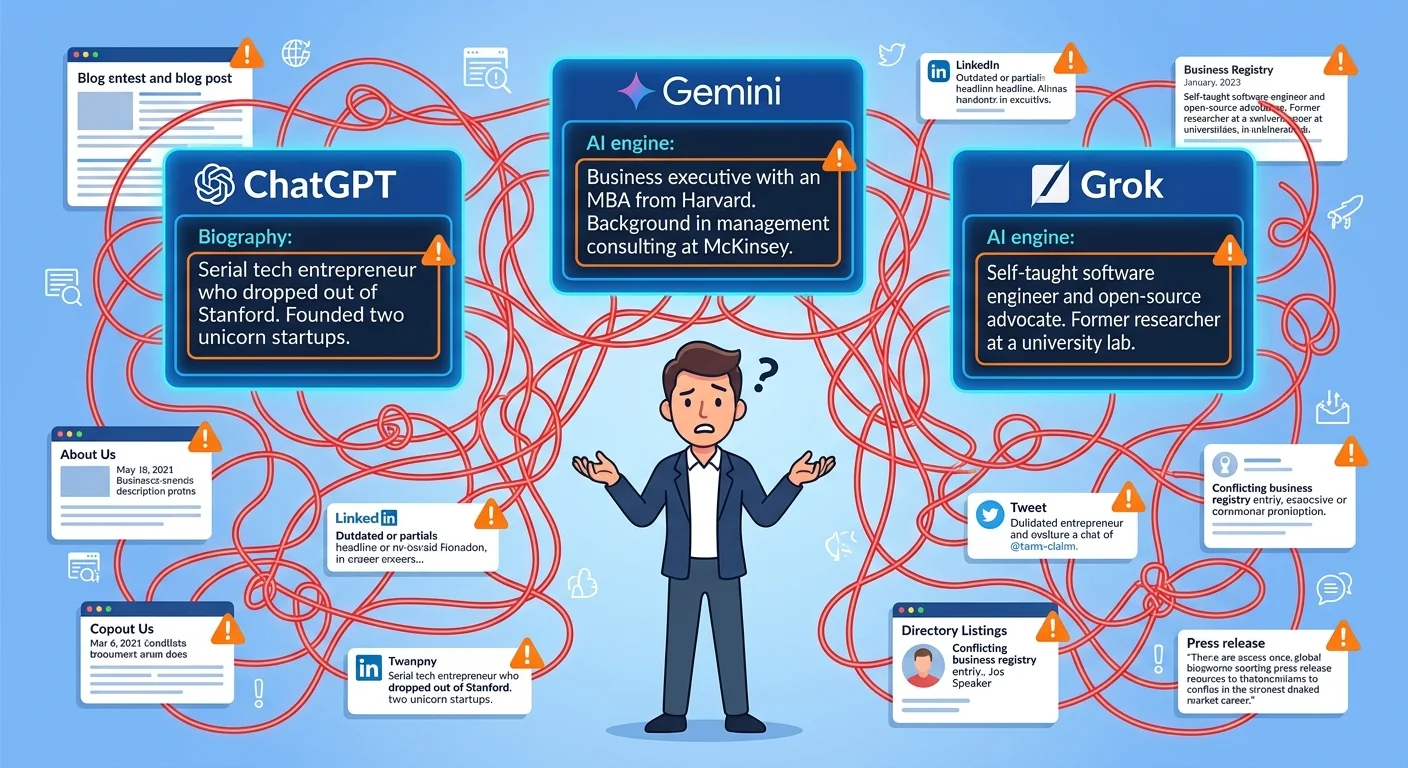
Your website says you're the founder. Your LinkedIn confirms it. Every colleague in your market knows it.
AI just named someone else.
Not because your credentials aren't real. Because AI can't parse them.
Here's what actually happens: someone asks ChatGPT or Gemini who founded your company. The engine scans available data sources. It finds fragments — some accurate, some outdated, some referencing someone else entirely. Without structured data telling AI which facts belong to which person, it fills the gaps.
AI guesses. And when it guesses wrong, it fabricates credentials, swaps founder names, or invents people who don't exist.
The result? Your competitor's name appears as your company's founder. Or AI invents someone who doesn't exist. Or it attributes your credentials to someone else in your industry.
This isn't a glitch. It's how these systems work when they encounter ambiguous data.
AI Engines Operate Without Human Judgment
AI doesn't fact-check the way humans do.
It doesn't call your office. It doesn't verify your business license. It synthesizes from whatever data it can access and parse. No schema telling AI "this person founded this business"? It guesses.
Sometimes the guess is close. Often it's catastrophically wrong.
The difference between accurate representation and fabrication comes down to whether you've given AI a machine-readable source of truth it can trust.
The Entity Disambiguation Problem
When AI encounters your name, it faces a technical challenge: which "you" is the query actually asking about?
Entity disambiguation is a documented technical challenge. According to research on entity linking published in ACM Computing Surveys, computational systems must disambiguate entity mentions by connecting them to a canonical entry in a knowledge base. Without clear entity markers, the system defaults to the most prominent match it can find.
If you share a name with someone more digitally visible, AI might pull their credentials instead of yours. If your professional history overlaps with another practitioner in your city, AI might conflate your practices into a single entity. If your website lacks schema defining you as a distinct person entity separate from your business entity, AI treats you and your business as interchangeable — or picks one and ignores the other.
Disambiguation requires structure. Structure requires schema. Schema requires intentional implementation.
Weak Signals Create Fabrication Opportunities
Every gap in your digital identity is an invitation for AI to guess.
No schema on your About page? AI infers your credentials from text patterns it thinks match professional biographies. No sameAs links connecting your website to verified profiles? AI can't confirm your identity across multiple sources, so it treats each mention as potentially unrelated. No structured relationship between your personal entity and your business entity? AI fabricates the connection based on whoever else it finds associated with your company name.
Weak entity signals don't just reduce your visibility. They actively create space for misinformation to take root.
| AI Identity Verification Factor | Strong Signal | Weak Signal |
|---|---|---|
| About Page Structure | Person schema with name, jobTitle, alumniOf, sameAs properties | Plain text bio with no markup |
| Cross-Platform Consistency | Identical credentials across website, LinkedIn, professional directories | Conflicting titles, dates, or affiliations |
| Entity Relationship Definition | Schema explicitly states "founder of [Business]" | Business mentions founder in unstructured text |
| Third-Party Verification | Multiple verified profiles linked via sameAs | Single platform with no external confirmation |
| Credential Attribution | alumniOf links to university with structured data | Degree mentioned in prose with no entity reference |
The Michael Walen Problem: A Real Example
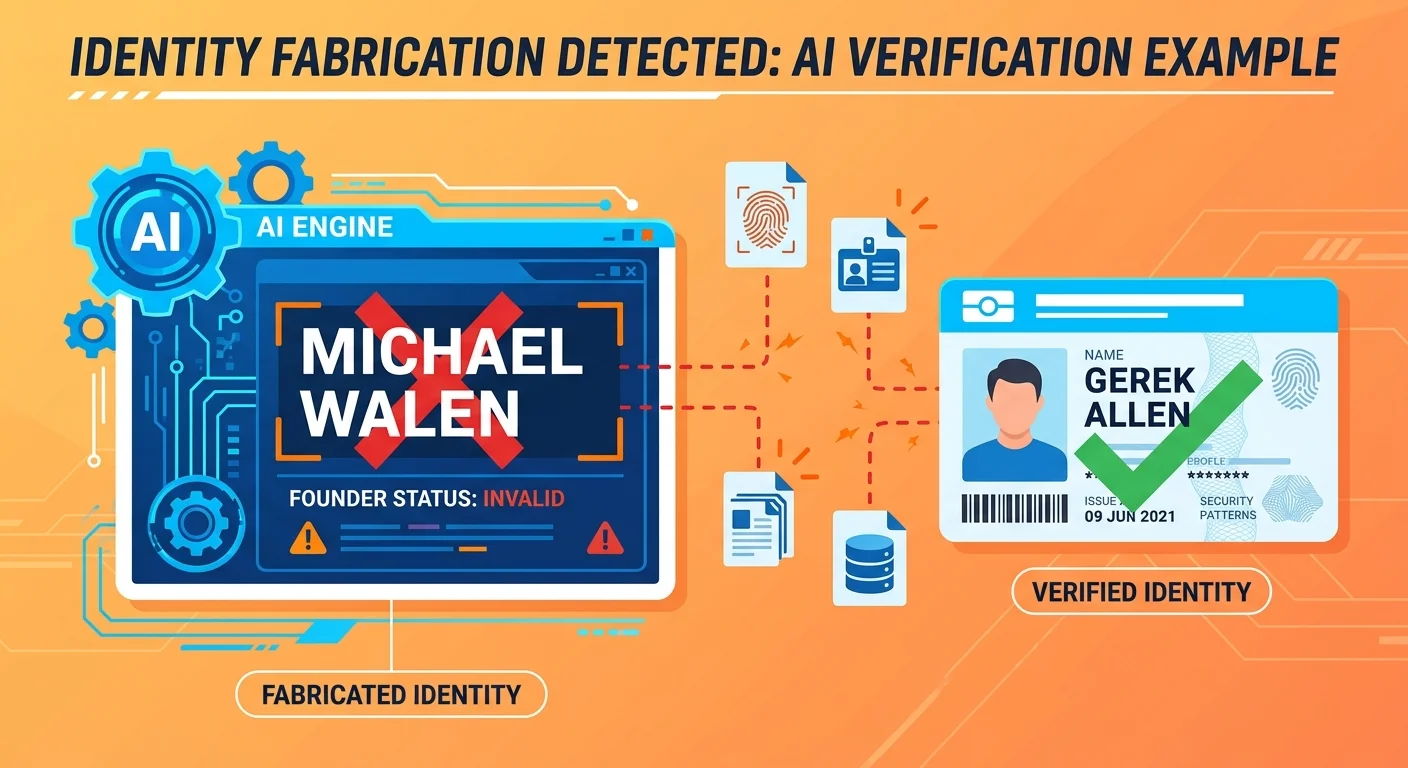
At least one AI engine fabricated "Michael Walen" as the founder of iTech Valet.
Not a typo. Not a minor error. A completely invented person assigned founder status for a real business. The actual founder is Gerek Allen. That's documented on the About page, in business filings, across professional profiles, and in every legitimate source that mentions iTech Valet's origin.
But AI didn't say Gerek Allen. It said Michael Walen.
This isn't theoretical danger. This is documented business risk. And it happened to a company actively building AI authority infrastructure — which means it's happening to practices with weaker entity signals too.
How the Fabrication Occurred
The fabrication likely stemmed from a combination of weak entity signals and missing schema.
If iTech Valet's About page lacked Person schema explicitly defining Gerek Allen as the founder — or if that schema wasn't linked to verified third-party profiles confirming the relationship — AI had no structured data to validate the claim. Instead, it synthesized from unstructured text sources.
Maybe it encountered another "Michael" associated with a different agency. Maybe it conflated data from an unrelated business entity. Maybe it found a broken reference in a directory that listed incorrect ownership information. Without schema, AI treats all text sources as equally valid.
The most prominent signal wins — even if it's wrong.
The Business Impact of Identity Fabrication
When AI names the wrong founder, the damage compounds.
A potential patient Googles your practice and asks ChatGPT who runs it. They get a name that doesn't match your website. That mismatch triggers distrust. They assume either the AI is unreliable or your business information is outdated.
Either way, they move on to a competitor whose entity signals are strong enough for AI to get right.
Worse: if the fabricated name spreads across multiple AI engines, it becomes the default answer for thousands of queries. Correcting it requires rebuilding entity trust from scratch — a process that takes months of structured content execution and schema verification.
The business cost isn't just lost visibility. It's active misattribution that hands your authority to a name that doesn't exist.
Why This Is Not an Isolated Incident
The Michael Walen fabrication is documentation of a systemic vulnerability.
Every founder without machine-readable identity infrastructure is one ambiguous data source away from the same problem. If your About page is just prose, AI has nothing to parse. If your schema exists but doesn't link to verified profiles, AI can't confirm it. If your professional history appears differently on LinkedIn than on your website, AI picks whichever version seems more authoritative — and that choice might be wrong.
This problem doesn't require malice or negligence. It requires nothing more than structural gaps in how your identity is presented to machines.
The only defense is redundancy: multiple verification layers that all point to the same canonical truth.
What Makes a Human Machine-Verifiable
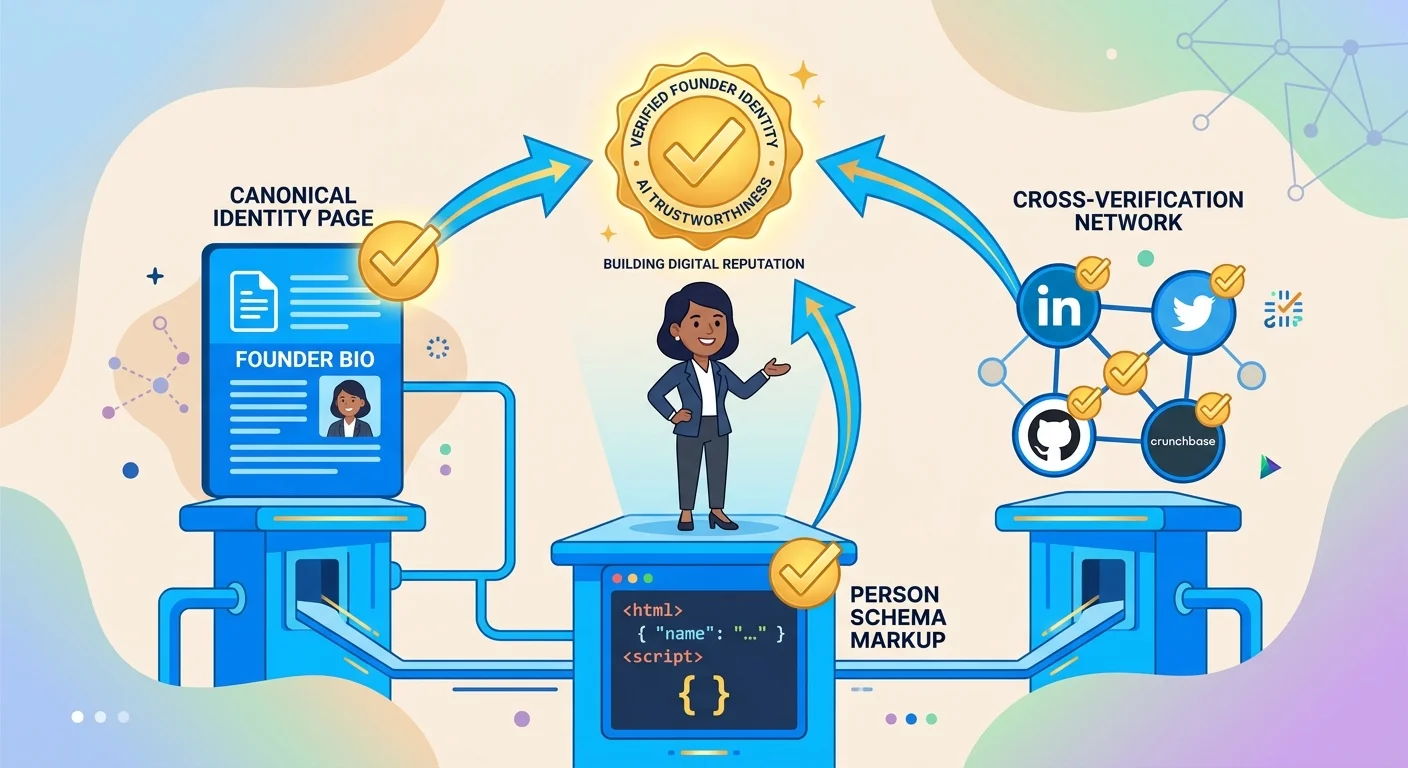
A machine-verifiable human is someone AI can trust because the technical infrastructure exists to confirm their identity across multiple sources.
Quick pause before we go further. If you're looking for a shortcut — a LinkedIn optimization hack or a one-time fix — this isn't it. Machine verification requires infrastructure. Schema. Cross-verification. Ongoing consistency across platforms.
If that feels like overkill, you're not the right fit. But if you're tired of AI naming competitors instead of you, you're in the right place.
This isn't about reputation. It's not about social proof. It's about structure.
Machine verification requires three things: a canonical URL that serves as your single source of truth, structured data that defines your factual attributes in machine-readable format, and cross-verification through links to third-party profiles that confirm those attributes independently. When all three layers exist, AI doesn't guess.
It validates.
The Three Pillars of Machine Verification
The framework has three components, and all three must be present.
Pillar 1: Canonical URL. The single page on your website that defines who you are. Usually your About page. Must live on your primary domain. Not a subdomain. Not a third-party platform.
Pillar 2: Structured Data. Person schema that tells AI your name, job title, credentials, and business relationships. The machine-readable version of your About page.
Pillar 3: Cross-Verification. Links to verified third-party profiles using the sameAs property. LinkedIn. University alumni directories. Licensing boards. Publications. Each link is a redundancy check AI uses to confirm your identity independently.
Together, these three layers create what we call the three pillars of founder-led AI trust. Face (your canonical page), Voice (your structured data), and Fact (your third-party verification network).
Without all three, the system breaks. AI either can't parse your identity, can't validate it, or can't distinguish you from someone else with a similar name or background.
Here's the thing: most chiropractors assume a complete LinkedIn profile solves this. It doesn't. LinkedIn is a verification node — not a canonical source. AI looks at your domain first. Third-party platforms are secondary.
If your domain can't tell AI who you are, LinkedIn can't save you.
Why Human-Readable Content Fails
Your About page might be beautifully written. Compelling prose. Clear narrative arc. Tells your story in a way that resonates with human readers.
AI doesn't care.
Here's the thing: AI engines don't read the way humans do. They don't extract meaning from narrative. They parse structured data. When AI encounters your About page, it's looking for entity markers. Schema properties that tell it "this is a person entity, here's their name, here's their job title, here's their relationship to this business entity."
If those markers don't exist, AI treats your About page like any other block of text. It might extract fragments. It might infer relationships. But it's guessing — and guesses create hallucinations.
This is why a pretty website without schema is structurally invisible. AI sees the page. It just can't understand what it's seeing.
WordLift defines an entity as a person, place, or thing that can be clearly identified and distinguished from other entities. Without schema, you're not an entity to AI. You're just text.
The trust issue extends beyond technical implementation. Pew Research Center data shows that public skepticism toward AI outputs remains high — which means when AI fabricates founder credentials, patients notice the inconsistency and disengage.
The Trust Compounding Effect
Once AI verifies your founder identity, that trust extends to your business.
This isn't metaphorical. It's operational.
When someone asks ChatGPT or Gemini who to trust for chiropractic care in their area, AI doesn't just evaluate your business entity. It evaluates the founder entity behind that business. If your founder entity has strong verification signals — schema, cross-referenced credentials, verified third-party profiles — AI interprets your business as authoritative by association.
If your founder entity is weak or fabricated, your business inherits that weakness.
Building entity trust at the founder level is foundational work. It's not about marketing your personal brand. It's about creating the technical infrastructure that allows AI to trust your business through you.
The Three Technical Layers of Founder Identity Protection
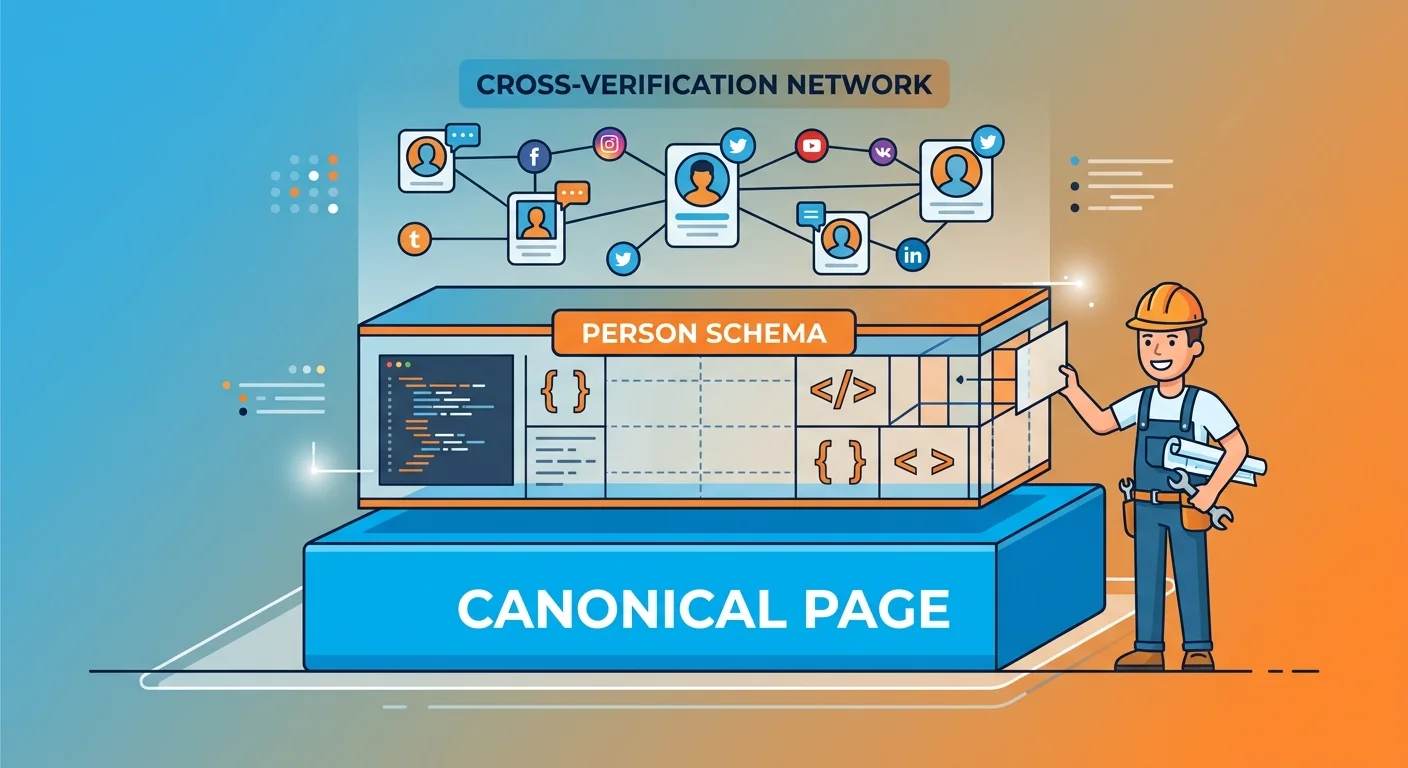
Identity protection isn't a single implementation. It's a three-layer architecture where each layer reinforces the others.
Think of it like building a structure. The foundation is your canonical identity page. The framework is your schema. The verification network is the crossbeams that keep everything stable.
Skip a layer and the whole thing collapses.
Layer 1: Canonical Identity Page
Your canonical identity page is the single URL that defines who you are.
This must live on your primary business domain. Not a subdomain. Not a Medium profile. Not your LinkedIn About section. Your domain.
Why? Because AI engines prioritize information hosted on the entity's own verified domain. Third-party platforms are treated as verification nodes — not sources of truth.
The page must contain verifiable facts written in prose that humans can read and understand. Your professional history. Your education. Your credentials. Your role in the business. Your published work if applicable.
This prose serves two purposes: it's the human-readable version of your identity, and it's the source text that your schema will reference.
Layer 2: Person Schema Implementation
Person schema is the structured data layer that translates your canonical page into machine-readable format.
According to Schema.org's Person specification, this markup defines properties like name, jobTitle, alumniOf, worksFor, and sameAs. These properties tell AI exactly who you are, what you do, where you were educated, and how to verify your identity through third-party sources.
This isn't theoretical markup. It's the same structured data framework Google relies on for E-E-A-T evaluation — Experience, Expertise, Authoritativeness, and Trustworthiness. AI answer engines use similar logic.
They verify the author before trusting the content.
Schema doesn't replace the prose on your canonical page. It annotates it. It tells AI which sentences contain facts about your education, which ones describe your role in the business, and which external profiles confirm those claims. Without schema, AI is reading your About page the same way it reads a blog post — as unstructured text with no entity markers.
With schema, AI reads your About page as a structured entity profile with verifiable attributes.
Layer 3: Cross-Verification Network
The third layer is your sameAs network: the collection of verified third-party profiles that confirm your identity independently.
Each sameAs link in your schema points to a profile on another platform where AI can validate the claims you've made on your canonical page. LinkedIn confirms your job title and professional history. Your university's alumni directory confirms your degree. Your state licensing board confirms your credentials. A publication's author profile confirms your published work.
These aren't just backlinks. They're verification anchors.
AI cross-references your schema claims against these third-party sources. The more sources that confirm the same facts, the higher your verification score. Redundancy reduces hallucination probability.
One source can be wrong. Three sources confirming the same fact? AI treats that as ground truth.
| Identity Protection Layer | Function | AI Impact | Implementation Difficulty |
|---|---|---|---|
| Canonical Identity Page | Single source of truth hosted on primary domain | Establishes entity existence and primary reference point | Low — content creation only |
| Person Schema | Machine-readable markup defining factual attributes | Enables AI to parse identity without guessing | Medium — requires technical precision |
| Cross-Verification Network | Third-party profiles linked via sameAs | Confirms identity across multiple independent sources | Low to Medium — depends on existing profiles |
How to Build Your Canonical Identity Page

Your canonical identity page is the foundation. Everything else builds on it.
This isn't a marketing exercise. It's a technical requirement. The page must contain verifiable facts structured in a way that both humans and machines can parse.
What Content Belongs on Your Canonical Page
Start with the facts AI needs to establish you as a distinct entity.
Your full name. Your current job title. The business you founded or lead. Your professional history — previous roles, notable projects, measurable outcomes if applicable. Your education. Degrees earned, institutions attended, graduation years if relevant. These become your alumniOf properties in schema.
Your credentials. Certifications, licenses, accreditations, memberships in professional organizations. Anything a third-party entity can verify. Your published work if it exists. Articles, books, research, case studies. Each publication becomes another verification node.
Do not include opinions, mission statements, or aspirational language. Those belong elsewhere. This page is a factual record.
URL Structure and Placement
The canonical page must live at a predictable URL on your primary business domain.
The standard is /about/ or /about-[yourname]/ depending on whether your business website focuses on the brand or the founder. For most chiropractic practices, /about/ works. For founder-led brands where the individual is the primary entity, /about-dr-[lastname]/ or similar can work.
What doesn't work: subdomains like founder.yourdomain.com, third-party platforms like Medium or LinkedIn, or dynamic URLs that change based on CMS structure.
AI looks for stability. The canonical URL should never change. If it does, you lose all the verification weight you've built.
Writing for Machines First, Humans Second
The prose on your canonical page must serve two audiences simultaneously.
Humans need narrative. They need to understand who you are and why you're credible. That narrative belongs on this page. But machines need structure. They need sentences that contain one verifiable fact each, written in a way that schema can annotate without ambiguity.
Example of human-first prose that machines can't parse: "I've spent the last 15 years helping patients achieve better health outcomes through evidence-based chiropractic care."
That's vague. AI doesn't know where you were educated, what credentials you hold, or what "15 years" refers to. It's narrative without data.
Example of machine-readable prose that humans can still understand: "I earned my Doctor of Chiropractic degree from Palmer College in 2009. I founded [Practice Name] in 2015 and have served over 3,000 patients in [City]."
That's structured. AI can extract "Doctor of Chiropractic," "Palmer College," "2009," "founded," and "[Practice Name]" as distinct facts. Schema can annotate each one.
The goal is factual clarity that reads naturally. Not robotic. Not keyword-stuffed. Just precise.
Person Schema: The Technical Infrastructure AI Reads
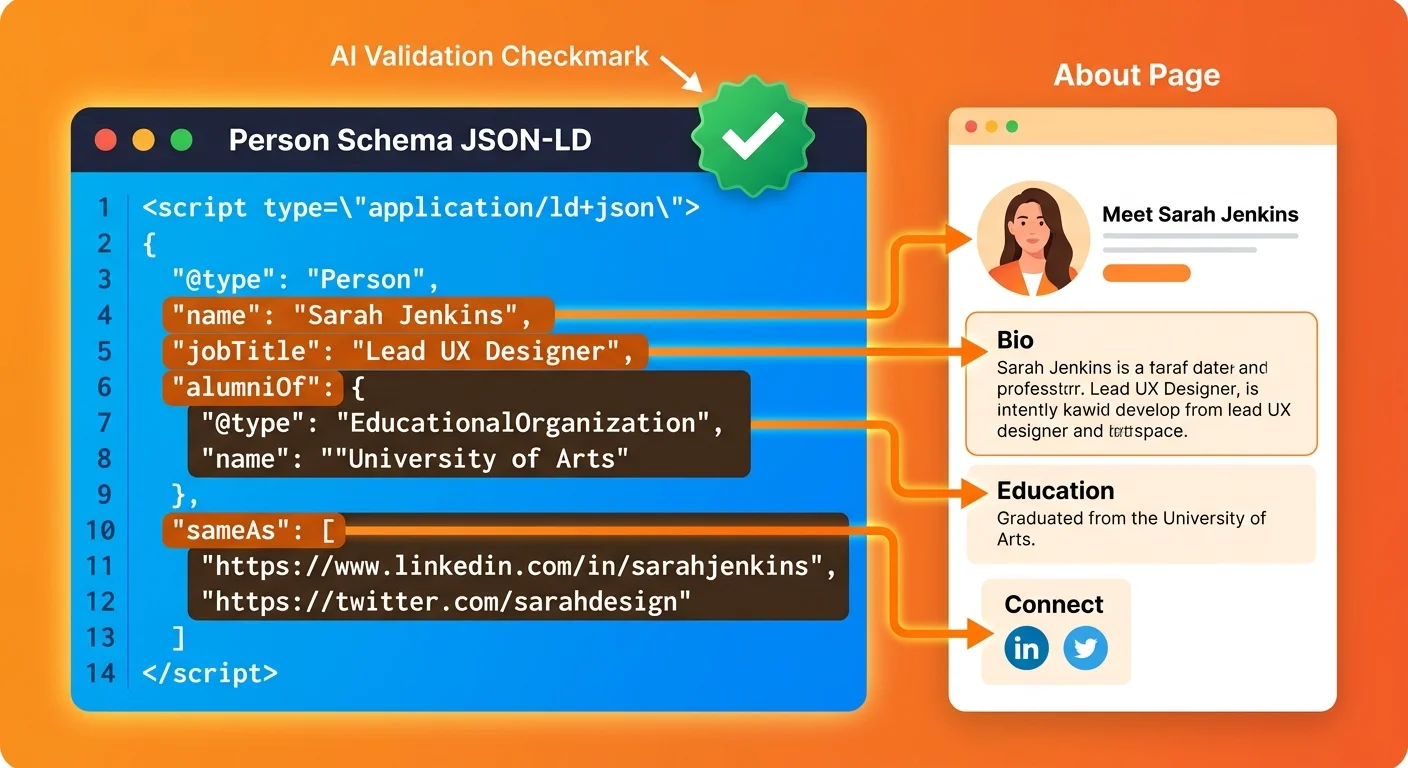
Schema is where identity protection becomes technical.
This is the markup that tells AI which parts of your canonical page contain facts, what those facts mean, and how to verify them. Without schema, your About page is invisible. With schema, it's a structured entity profile AI can parse and trust.
Required Schema Properties for Founders
At minimum, your Person schema must include these properties:
- name — Your full legal or professional name as it appears on official documents
- jobTitle — Your current role (e.g., "Founder," "Doctor of Chiropractic," "CEO")
- worksFor — Links your person entity to your business entity using schema reference
- alumniOf — References your educational institutions as structured entities
- sameAs — An array of URLs pointing to verified third-party profiles
These five properties create the baseline structure AI needs to recognize you as a distinct entity separate from your business.
Additional properties strengthen the entity but aren't strictly required: description (a brief professional summary), knowsAbout (areas of expertise), hasCredential (professional licenses or certifications), and publishingPrinciples (if you publish content regularly).
How AI Validates Schema Claims
Schema isn't a trust signal by itself. It's a promise that AI verifies against external sources.
When your schema says alumniOf: Palmer College, AI looks for confirmation. Does Palmer College's website list you as an alum? Does your LinkedIn profile mention the same degree? Does any third-party source corroborate this claim?
If multiple sources confirm it, AI treats it as fact. If no sources confirm it — or worse, if sources contradict it — AI downgrades your entity trust.
This is why schema must match reality exactly. A single discrepancy between your schema and your verified profiles can trigger AI to treat your entire entity as unreliable.
Common Schema Errors That Weaken Trust
Most schema failures aren't syntax errors. They're structural errors that pass validation but confuse AI.
Incomplete sameAs arrays. If you list LinkedIn but not your university profile, AI can only partially verify you. More sources = more trust.
Mismatched data across properties. If your jobTitle says "Founder" but your worksFor property doesn't reference your business entity, AI sees a contradiction.
Unverifiable alumniOf claims. If you claim a degree from an institution that doesn't have structured alumni data, AI can't confirm it. Use institutions with strong entity presence.
Schema that contradicts page content. If your prose says you graduated in 2009 but your schema references a 2010 date, AI flags the mismatch.
Every error weakens the entity. Fix them all or don't deploy schema at all.
| Schema Property | Verification Method AI Uses | Trust Weight |
|---|---|---|
| name | Cross-references against third-party profiles and business filings | High — mismatches trigger entity disambiguation errors |
| jobTitle | Validates against LinkedIn, business entity data, and public records | Medium — inconsistencies weaken but don't break entity |
| alumniOf | Checks university alumni databases and LinkedIn education section | High — verifiable credentials compound trust significantly |
| sameAs | Traverses each URL to confirm profile exists and matches person entity | Critical — more verified profiles = exponentially higher trust |
| worksFor | Validates relationship between person entity and business entity | High — broken or missing link treats founder as unrelated to business |
Linking Your Entity to the Knowledge Graph
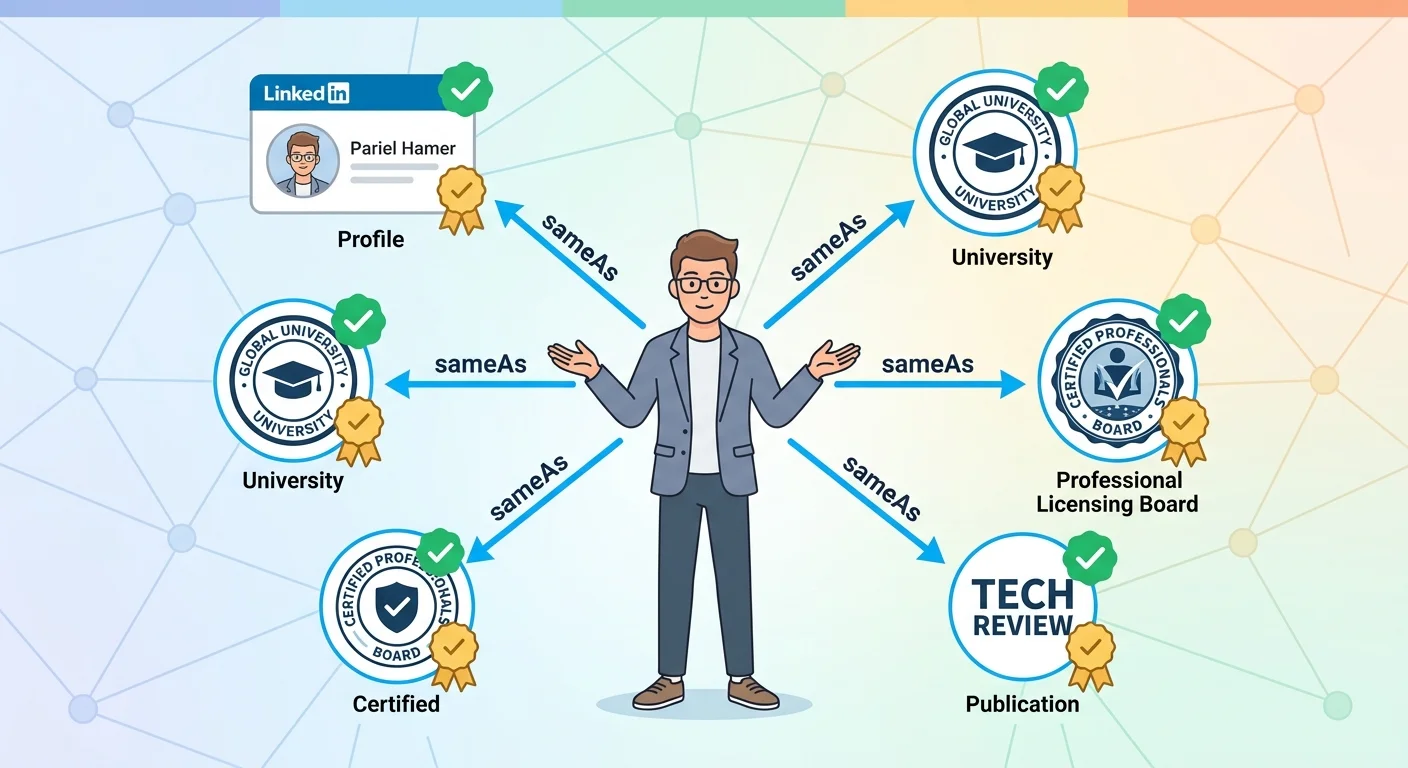
Your canonical page and schema establish your entity. Your sameAs network connects that entity to the broader knowledge graph.
This is how AI confirms you're not just a well-structured claim — you're a verified individual with a digital footprint that multiple independent sources corroborate. To anchor your entity in the knowledge graph, you need redundancy.
One link is weak. Three links are credible. Five or more links are authoritative.
What Qualifies as a Verified Third-Party Profile
Not every profile counts. AI prioritizes sources it can parse and trust.
LinkedIn is the most common sameAs node for professional identity. AI can extract structured data from LinkedIn profiles — job titles, education, company affiliations, endorsements. University alumni directories are high-trust sources if your institution maintains a public directory with structured data. These confirm educational credentials directly from the issuing institution.
Professional licensing boards and accreditation bodies are verification gold. If your state maintains a public database of licensed chiropractors and you're listed there, that's a source AI treats as ground truth. Publications with author profiles work if you've written for reputable outlets. An author page on a journal, blog network, or industry publication confirms your expertise in a specific domain.
What doesn't qualify: personal blogs with no third-party verification, social media platforms without structured data (Instagram, Facebook), or any profile you control entirely with no external validation.
The Redundancy Principle
The more independent sources that confirm your identity, the lower the probability AI fabricates or misattributes facts.
One sameAs link is better than none. But it's not redundant. If that single profile is outdated or contains errors, AI has no fallback. Three sameAs links create cross-verification. If two sources agree and one conflicts, AI defaults to the majority consensus.
Five or more sameAs links create a verification network. At this level, AI treats your entity as highly authoritative because multiple independent sources corroborate the same facts.
This is the technical mechanism behind entity trust. It's not reputation. It's redundancy.
How to Audit Your Current Verification Network
Most founders have profiles scattered across platforms. The question is whether those profiles are structured, consistent, and linked.
Start by listing every platform where you have a professional presence. LinkedIn, university directories, licensing boards, publications, professional associations, Crunchbase if applicable. For each profile, check three things:
- Does the profile contain structured data AI can parse? (Many platforms use schema or similar markup.)
- Is the information on this profile consistent with your canonical page? Same job title, same credentials, same dates?
- Is this profile linked from your canonical page via the sameAs property in your Person schema?
Any profile that fails one of these checks is a potential vulnerability. Fix the data, add the link, or remove the profile from your verification network entirely.
If you want to see exactly what AI engines say about you right now, run the AI Visibility Check. It'll show you whether AI can correctly identify you as your business's founder — or whether it's pulling incorrect data from unverified sources.
Common Mistakes That Invite AI Hallucinations
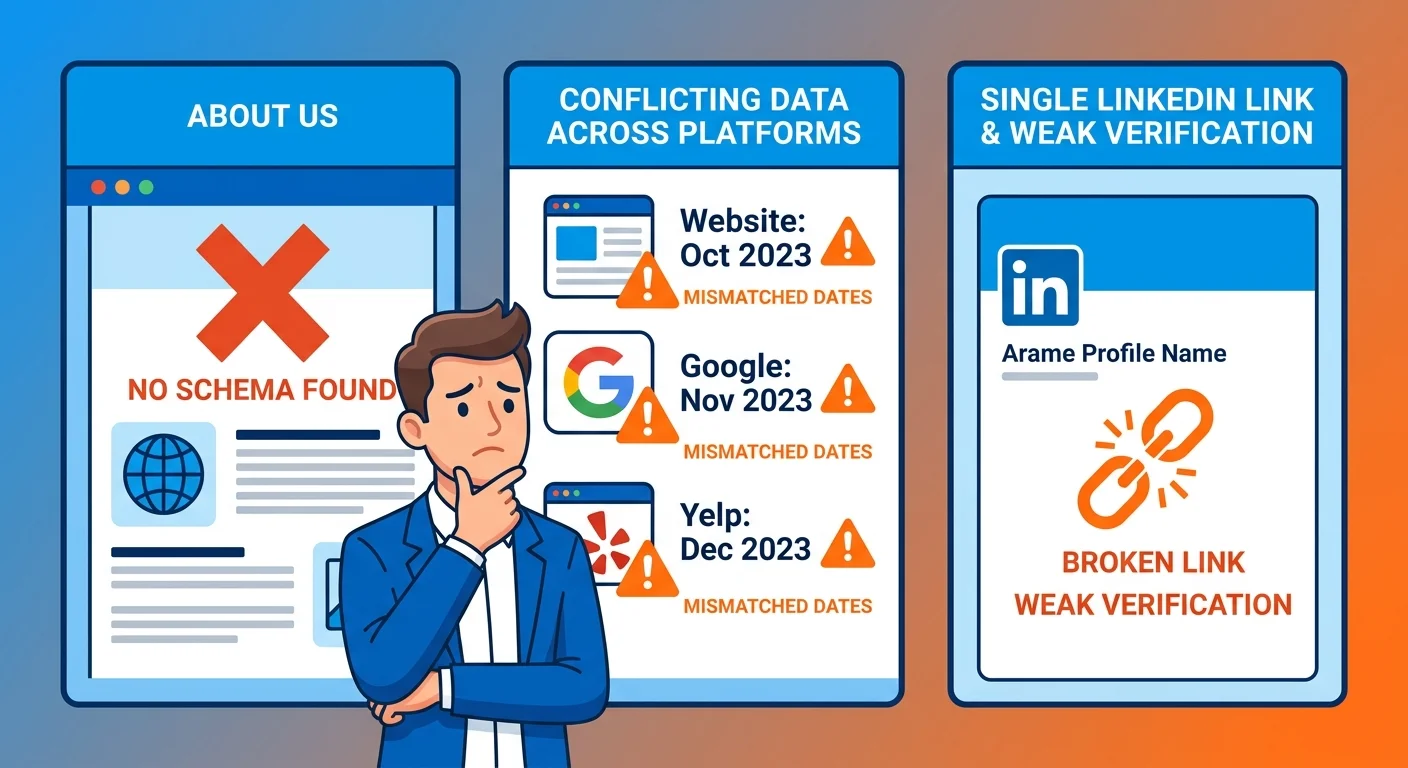
Most AI hallucinations about founders stem from structural gaps, not malicious intent.
The errors are predictable. And fixable.
Mistake 1: No Structured Data on Your About Page
Your About page has prose. Maybe a headshot. Maybe a list of credentials.
But no schema.
AI reads that page the same way it reads a blog post. It sees text. It infers some facts. But it has no structured entity markers telling it "this person founded this business" or "these are verified credentials." Without schema, AI guesses.
Sometimes the guess is close. Often it's wrong.
And here's the kicker: if a competitor in your market has schema and you don't, AI defaults to the entity it can parse. That means your competitor gets cited as the authority even if your credentials are stronger. No schema = structural invisibility.
You're not just losing visibility. You're creating space for fabrication.
Mistake 2: Conflicting Information Across Platforms
Your website says you graduated in 2009. LinkedIn says 2010. A professional directory lists 2008.
Which one is AI supposed to believe?
It can't ask you. So it picks the source it considers most authoritative — and that choice might not align with reality. Conflicting data across platforms doesn't just weaken your entity. It actively triggers disambiguation errors. AI treats you as multiple potential entities and has to guess which one matches the current query context.
The fix is tedious but necessary: audit every professional profile, cross-check dates and credentials against your canonical page, and correct any discrepancies.
Every profile must say the same thing.
Mistake 3: Weak or Missing Cross-Verification
You have a canonical page. You have schema. But your sameAs array is empty — or it only points to LinkedIn.
That's not verification. That's a single point of failure.
If LinkedIn's data is wrong or outdated, AI has no fallback. It either uses the incorrect LinkedIn data or defaults to guessing based on unstructured sources elsewhere. Cross-verification requires multiple independent sources. University directory. Licensing board. Professional association. Publication author page. Each one is another data point AI uses to confirm your identity.
Without redundancy, you're one bad data source away from a hallucination.
This is not for the founder who believes word-of-mouth is enough. If you think your reputation will carry itself without technical infrastructure, AI will name someone else. Word-of-mouth doesn't register in a knowledge graph. Schema does.
| Identity Mistake | Hallucination Risk | Fix |
|---|---|---|
| No schema on About page | High — AI guesses founder identity from unstructured sources | Implement Person schema with required properties |
| Conflicting credentials across platforms | High — AI treats you as multiple entities or picks incorrect data | Audit all profiles, standardize facts, correct discrepancies |
| Weak sameAs network (0-1 links) | Medium to High — no redundancy for AI to verify claims | Add 3-5 verified third-party profiles to sameAs array |
| Schema contradicts page prose | Medium — AI flags entity as unreliable | Ensure schema annotations match visible content exactly |
| No worksFor property linking to business | Medium — AI treats founder and business as unrelated | Define founder-business relationship in both Person and Organization schema |
Why a LinkedIn Profile Is Not Enough
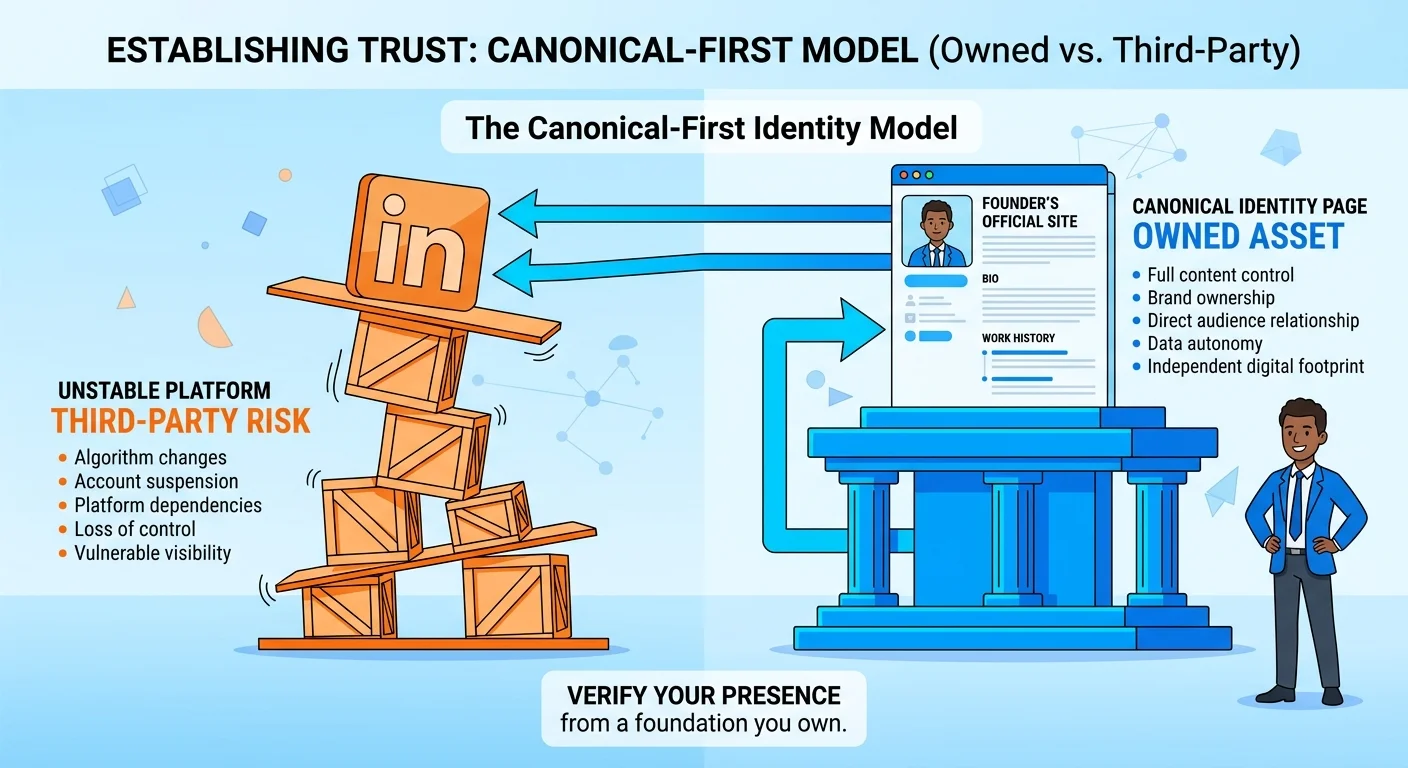
Most founders assume a complete LinkedIn profile solves the identity problem.
It doesn't.
LinkedIn is a verification node. It's not a canonical source. The distinction matters.
LinkedIn as a Verification Node, Not a Source of Truth
When AI evaluates your identity, it looks for a canonical URL — a single page on your own domain that serves as the primary reference point.
LinkedIn doesn't qualify. You don't control the platform. You don't control the data structure. LinkedIn could change its schema implementation tomorrow and your profile would lose its verification weight.
LinkedIn's job in your identity architecture is to confirm claims made on your canonical page. It's a third-party source AI uses to cross-check your credentials and professional history. But if your canonical page is weak or missing, LinkedIn becomes your de facto identity anchor — and that's a vulnerability.
This is the same principle behind AEO vs SEO. SEO optimizes for where users might go. AEO optimizes for where AI actually looks.
AI looks at your domain first. Third-party platforms are secondary.
Platform Risk: What You Don't Control Can Change
LinkedIn could change its terms of service. It could alter how profiles are displayed to third parties. It could deprecate the structured data that AI currently uses to parse profiles.
You'd have no recourse. Your identity infrastructure would break overnight.
This is platform risk. Any identity system that relies entirely on third-party platforms is fragile. Your canonical page on your own domain is the only identity asset you fully control. It's hosted on infrastructure you manage. The schema is yours to maintain. The content updates on your timeline.
If LinkedIn disappears tomorrow, your canonical page still exists. Your identity remains intact.
The Canonical-First Model
The correct architecture is canonical-first, verification-second.
Build your identity on your own domain. Implement Person schema. Write factual prose that humans can read and machines can parse. Then link outward to LinkedIn, university directories, licensing boards, and publications. Each outbound link is a sameAs reference that tells AI "this third-party profile confirms the facts on my canonical page."
Never the reverse. Never build your identity on LinkedIn and hope your website gets noticed.
AI prioritizes the domain. Always.
FAQ
What is the difference between a brand entity and a person entity?
A brand entity represents your business — the organization itself as a distinct entity with its own attributes like name, address, services, and reputation. A person entity represents you as an individual — your identity, credentials, expertise, and professional history.
AI needs to understand both entities and the relationship between them. This is defined through schema properties like founder, worksFor, and employee. When AI recognizes you as the founder of your business entity, it extends trust from your personal credentials to your business's authority.
If this relationship isn't explicitly defined in schema, AI treats you and your business as separate, unrelated entities. That breaks the trust transfer and weakens both your personal authority and your business's visibility.
Can AI just learn who I am from my website's about page?
Not reliably.
While an about page provides the content AI needs, unstructured text is inherently ambiguous. AI can extract fragments — maybe your name, maybe a job title — but it can't parse facts with certainty. Person schema solves this by annotating the text. It tells AI "this sentence contains the founder's educational background" and "this phrase defines their professional credentials."
Without that annotation, AI treats your about page like any other block of prose — useful for context but not trustworthy as an entity definition. Structured data isn't a replacement for your about page. It's the markup that makes your about page machine-readable.
How does having a "machine-verifiable" identity help my business?
When AI verifies you as a credible founder, it interprets your business as credible by extension.
This is the trust transfer mechanism. Patients don't just ask AI "who's the best chiropractor near me." They ask "who founded this practice" and "what are the chiropractor's credentials." If AI can answer those questions confidently and correctly, your business becomes the recommended answer. If AI can't verify your founder identity — or worse, if it hallucinates incorrect details — that uncertainty transfers to your business.
Potential patients see inconsistencies and move on to competitors whose entity signals are stronger.
Building a machine-verifiable identity isn't about personal branding. It's about protecting your business from the downstream consequences of weak founder entity signals. This is the infrastructure work that makes The AI Authority Engine effective. Without it, AEO content execution compounds on a foundation AI can't trust.
What is the first step to building my personal knowledge graph?
Start with the canonical identity page.
Create a dedicated page on your website — typically at /about/ — that contains verifiable facts about your professional history, education, credentials, and role in your business. Then implement Person schema on that page. At minimum, include your name, job title, the business you founded (using the worksFor property), your educational background (using alumniOf), and links to verified third-party profiles (using sameAs).
Once the canonical page and schema are live, audit your third-party profiles to ensure they match. Any conflicts between your canonical page and external profiles create disambiguation errors.
This is foundational work. Everything else — AEO content, citation velocity, semantic depth — builds on this structure.
Is it possible to completely prevent AI hallucinations about me?
No system is perfect. AI engines operate probabilistically, and even with strong entity infrastructure, they can still produce incorrect outputs under certain conditions.
But the probability of hallucination drops dramatically when you have:
- A canonical identity page with verifiable facts
- Person schema that defines your entity in machine-readable format
- A verification network of 3-5 third-party profiles that confirm your credentials independently
Without these layers, AI fabrications are not just possible — they're likely. With these layers, the risk becomes statistically marginal.
The question isn't whether you can eliminate all risk. The question is whether you're willing to leave your founder identity unprotected while competitors build the infrastructure AI trusts.
Do I need to hire a developer to implement Person schema?
Schema implementation isn't complex from a coding perspective — the syntax is straightforward and well-documented.
But it requires precision. A single mismatched property, an incorrectly formatted sameAs URL, or a conflict between your schema and your page content can weaken your entity rather than strengthening it. Most founders attempting DIY schema make structural errors that pass validation but confuse AI. They include properties that contradict each other, reference entities that don't exist, or create circular relationships that break disambiguation logic.
If you understand entity relationships and have technical fluency with JSON-LD, you can implement it yourself. If you don't, the risk of creating a faulty entity definition outweighs the cost of professional implementation.
This is not a place to cut corners.
How long does it take for AI engines to recognize my verified identity?
Entity recognition isn't instant, but it's not a six-month timeline either.
Initial recognition — AI correctly parsing your name and associating it with your business — can happen within weeks of deploying schema and cross-verification. This is the point where AI stops guessing and starts referencing your structured data. Full authority establishment — AI consistently naming you as a trusted source across multiple query contexts — compounds over time. It requires not just identity infrastructure but ongoing content execution that reinforces your expertise.
I've seen practices show measurable improvements in AI citation accuracy within 60-90 days of deploying a complete founder entity infrastructure. But like all authority work, the compounding effect accelerates the longer the system runs.
Conclusion
AI engines are already answering questions about your expertise, your credentials, and your business.
The only variable is whether they're saying your name or fabricating someone else's.
This is not a future problem. It's operational right now. Every query about chiropractors in your market, every question about founder credentials in your industry, every patient asking AI who to trust — those answers are being generated with or without your input. If your founder identity lacks structure, AI fills the gaps.
Sometimes it guesses correctly. Often it doesn't. And once incorrect information propagates, correcting it requires months of entity rebuilding.
Word-of-mouth doesn't work when AI is telling people the wrong word. A beautiful About page doesn't register if machines can't parse it. LinkedIn is a verification node, not a source of truth. The practices building machine-verifiable founder identities now are the ones AI will trust when someone asks who's credible.
The ones waiting for this to become obvious will find their competitors already own the answer.
There's no version of this where doing nothing is a safe play. AI is already answering questions about your credentials. Either your name is in the answer or someone else's is. That gap widens every month it goes unaddressed.
The AI Visibility Check shows you exactly what ChatGPT, Gemini, and Grok say when someone asks about your credentials and expertise. It takes 15 minutes. If AI can't verify who you are, you'll see the gaps immediately.
The machine-verifiable human isn't optional. It's the only version of you AI can trust.
621 Enterprises, Inc. | Copyright 2026 | All rights reserved