
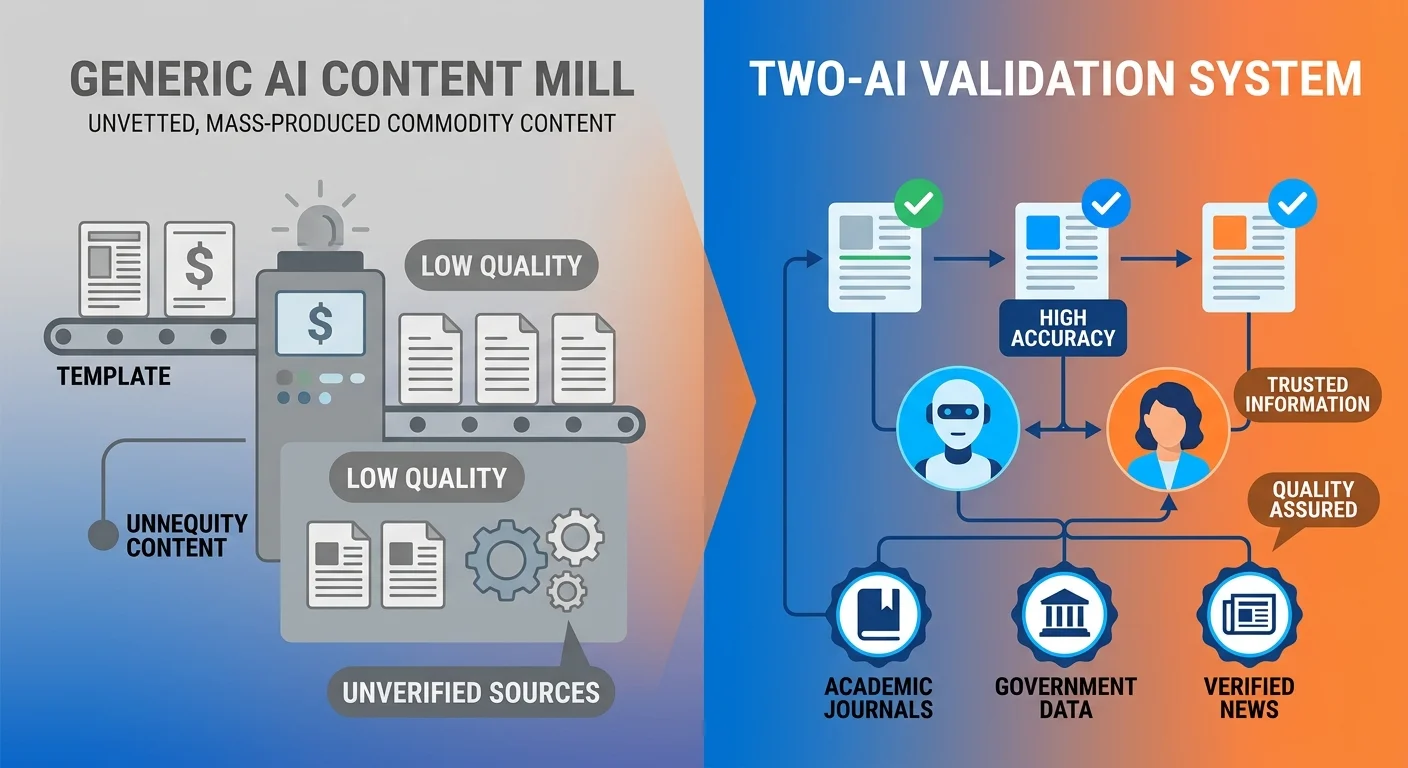
The Two-AI Validation System: How We Engineer Fact-Checked Chiropractic Content
iTech Valet's Two-AI Validation System is a proprietary content methodology designed to eliminate AI hallucinations and ensure factual accuracy. It uses Google's Gemini for initial research and final validation of all sources and claims, paired with Anthropic's Claude for drafting and refining the written content. This multi-layered process guarantees that all published AEO content is fact-checked, trustworthy, and authoritative enough for AI answer engines to cite.
It works by making two AIs check each other's work. Gemini researches and validates. Claude writes. Gemini checks Claude's writing. Then Claude refines based on what Gemini found. Nothing gets published until they both agree it's factually accurate.
We don't use two AIs to sound complicated. We use two because healthcare content doesn't get a margin for error. When you're publishing information that patients will use to make decisions about their health, "pretty close" isn't good enough. The Two-AI Validation System ensures that every statistic cited, every claim made, and every recommendation offered can be traced to a verifiable institutional source. We don't publish vibes. We publish receipts.
Last Updated: April 27, 2026
Why Single-AI Content Fails the Accuracy Test
Here's the problem with how agencies write chiropractic content: the AI checking the work is the same AI that wrote the work.
Most shops use one model — ChatGPT researches, writes, ships. That's it.
When the model validating the claim is also the model that generated the claim, there's no external verification. It can't catch its own reasoning errors. Can't flag sources it made up. Can't identify statistical drift it introduced three paragraphs back.
It's like grading your own test. The incentive structure breaks.
The Hallucination Problem Healthcare Content Can't Afford
AI hallucinations aren't theoretical.
They're documented. Studied. Happening right now across every major language model in production.
Stanford's research on AI factual accuracy shows that large language models confidently generate false information when they don't have verified data to reference. They fill gaps with plausible-sounding statements that aren't grounded in reality.
For a blog about email marketing tactics? Annoying.
For healthcare content that patients use to make treatment decisions? Dangerous.
When you're publishing information about spinal adjustments, contraindications for certain techniques, or health outcomes patients can expect — fabricated statistics aren't just wrong. They're liability exposure.
The moment a patient reads inaccurate health information on your site, your authority is compromised.
And if that misinformation influences a treatment decision?
You're not just invisible to AI engines anymore. You're a reputational risk.
Why Most Agencies Skip Validation Entirely
The industry sells hopium.
AI content became the shiny new thing. Marketing agencies jumped on it fast — not because they engineered a better process, but because clients asked for it and it was cheaper than hiring writers.
So they slapped together ChatGPT prompts. Called it "AI-powered content strategy." Moved to the next client.
No validation layer. No fact-checking protocol. No institutional source verification.
Just vibes and volume.
McKinsey's 2024 AI report identifies inaccuracy as the single most significant risk organizations face when deploying generative AI.
It's not speed. It's not cost.
It's the fact that these models produce confidently wrong output at scale.
And most agencies building AI content workflows aren't addressing that risk. They're ignoring it and hoping you don't notice until after the retainer clears.
The Real Cost of Publishing Unverified Claims
When a chiropractic practice publishes AI-generated content with factual errors, three things break immediately.
Patient trust. The first time a prospective patient reads something that contradicts what their PCP told them — or worse, contradicts established clinical guidelines — they leave. They don't email you to ask for clarification. They close the tab and Google someone else.
Professional reputation. Your peers notice. Other chiropractors in your area see the content. If it's sloppy or inaccurate, that assessment sticks. Referral networks dry up fast when your digital presence suggests you don't care about precision.
AI engine trust. This is the part most practices don't see yet. When answer engines crawl your content and can't verify the claims you're making against institutional sources, they don't cite you. They cite the competitor whose content passed validation. You're not penalized. You're just invisible.
Publishing unverified AI content doesn't just fail to build authority.
It actively erodes the trust signals you need to be discoverable.
| Approach | Research Method | Fact-Checking Layer | Error Risk | Trust Impact |
|---|---|---|---|---|
| Single-AI Content | One model researches and writes | None — same AI validates its own output | High — hallucinations and drift go undetected | Low — unverified claims reduce patient and AI engine trust |
| Human-Only Content | Expert writer researches and drafts | Self-review or editorial oversight | Moderate — subject to writer bias and knowledge gaps | High — but scales poorly and costs significantly more |
| Two-AI Validation System | Gemini researches, Claude writes, Gemini re-validates | External AI validates all claims against institutional sources | Low — multi-pass verification catches errors before publication | High — every claim is traceable to verified institutional sources |
How the Two-AI Validation System Works
We use two AI engines because they're good at different things.
And because the second one doesn't trust the first one.
Gemini handles research and validation. Claude handles drafting and refinement. Neither engine operates without oversight from the other.
This isn't about making the process more complicated for complexity's sake. It's about introducing an adversarial validation layer that single-AI workflows can't replicate.
When Gemini validates sources at the research phase, it's building a brief Claude must follow.
When Gemini re-validates the draft Claude produces, it's auditing whether the written content stayed within the boundaries of what can actually be verified.
That tension — between the AI that researched and the AI that wrote — is what catches errors before they reach publication.
The AI Authority Engine builds infrastructure and content execution designed to make practices the answer AI engines recommend. The Two-AI Validation System is the quality control mechanism that ensures the content feeding that engine is accurate enough to be trusted.
Why We Use Gemini for Research
Gemini has direct access to Google's institutional database ecosystem.
When it validates a source, it's cross-referencing against .gov repositories, .edu research archives, and peer-reviewed medical journals indexed in real time.
It's also better at disambiguating entities. If we're writing about spinal manipulation techniques, Gemini can pull verified clinical definitions from the American Chiropractic Association, cross-check contraindications from NIH databases, and flag any statistical claims that don't trace to a published study.
TechCrunch's AI model comparison highlights this strength. Gemini's integration with Google's search infrastructure gives it a verification edge that closed models like GPT-4 can't match.
It's not perfect. No AI is.
But when the task is "find institutional sources and validate every claim before writing starts," Gemini's architecture is purpose-built for that workflow.
Why We Use Claude for Writing
Claude is better at tone, voice, and reasoning through complex arguments without losing narrative coherence.
When we're building content that has to sound like it came from a founder with 20 years of experience — not a chatbot optimizing for keyword density — Claude handles that calibration more naturally than Gemini.
It's also better at maintaining POV consistency across long-form content. If we're deploying friction in Slot 1, conviction in Slot 4, and a directional close in Slot 5, Claude tracks that narrative thread without drifting into generic hedging.
Gemini can write. But Claude writes like a human who gives a damn about the outcome.
The division of labor isn't arbitrary.
Gemini validates what's true. Claude communicates why it matters.
The Validation Loop That Prevents Errors
The real value isn't just using two AIs.
It's the back-and-forth between them.
Gemini builds the research brief. Claude drafts the article. Gemini audits the draft and flags anything that doesn't trace to the original verified sources. Claude revises based on that feedback.
If Claude introduced a claim Gemini can't verify, it gets cut or rewritten with a traceable source.
If Claude paraphrased a statistic in a way that drifts from the original data, Gemini catches it and sends it back for correction.
No content moves to final review until both engines agree: every claim is verified, every source is institutional, and nothing was fabricated to fill a gap.
That's the loop. Research → Draft → Validate → Refine.
It's not faster than using one AI. But it's accurate in a way single-model workflows can't replicate.
| AI Engine | Primary Function | Key Strength | Role in System |
|---|---|---|---|
| Google Gemini | Research & Validation | Direct access to institutional databases, real-time source verification, entity disambiguation | Phase 1: Build verified research brief; Phase 3: Audit draft for claim accuracy and source traceability |
| Anthropic Claude | Drafting & Refinement | Natural language generation, tone calibration, voice consistency, nuanced reasoning | Phase 2: Draft article using verified brief; Phase 4: Refine content based on validation feedback |
The Four Validation Phases
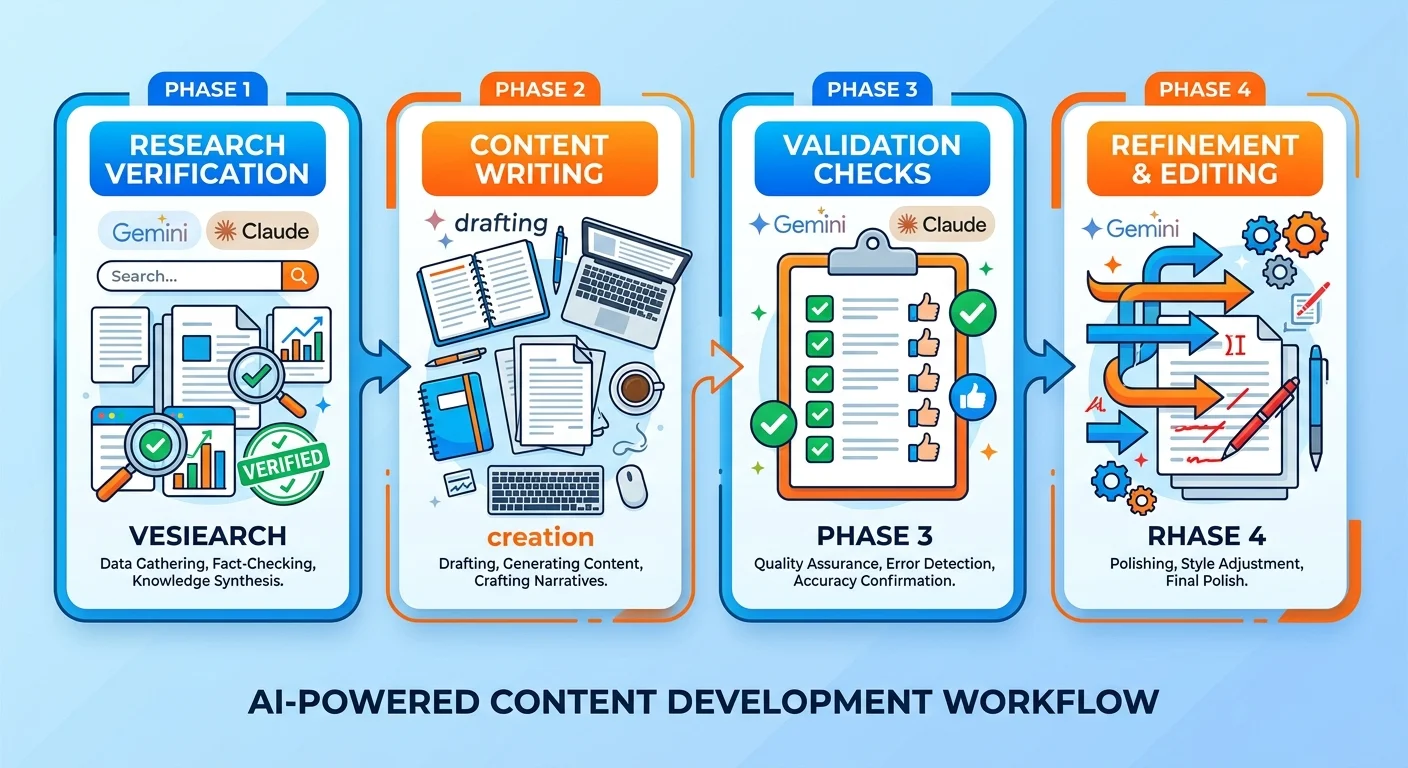
Every article we publish moves through the same four-phase process.
No shortcuts. No "good enough for now" drafts that ship early because a client's in a hurry.
Each phase has a single job. And the next phase doesn't start until the previous one passes its quality gate.
Phase 1: Gemini Research & Source Validation
Gemini starts by building the research brief.
It pulls external sources — institutional only, Tier 1 and Tier 2 verified — and validates them against .gov databases, .edu repositories, and peer-reviewed medical journals.
Every source gets checked. Every claim gets traced.
If Gemini can't verify a piece of data, it doesn't go in the brief. No "probably true" claims. No "commonly believed" statistics that don't trace to a published study.
The output of Phase 1 is a research brief Claude will use to draft the article. That brief includes the direct answer, the external evidence map, FAQ seeds, and strategic directives.
Everything in that brief is verified before Claude sees it.
This is the foundation. If Phase 1 is sloppy, every phase after it compounds the error.
Building entity trust starts with verifiable claims. AI engines can't cite what they can't confirm. Gemini's research phase ensures every claim we publish can be traced to an institutional source AI engines already trust.
Phase 2: Claude Drafting
Claude takes the verified research brief and drafts the article.
It integrates voice, deploys POV in the five hardcoded slots, addresses all five intent layers, and builds the narrative structure that makes the content readable.
But it doesn't invent claims. It doesn't add statistics Gemini didn't verify. It doesn't paraphrase institutional data in a way that drifts from the source material.
Claude's job in Phase 2 is execution — turning verified research into content that sounds like it came from a human with experience, authority, and a point of view.
The draft that comes out of Phase 2 is structurally complete.
H2 sections. H3 subsections. Tables. FAQ. Directional conclusion — all there.
But it's not final yet. Because Phase 3 is where we find out if Claude stayed inside the verified boundaries Gemini set.
Phase 3: Gemini Re-Validation
Gemini audits the draft Claude produced.
It cross-checks every claim against the original research brief. Every statistic gets verified. Every source gets re-confirmed. Every paraphrased piece of data gets tested for drift.
If Claude introduced something Gemini can't verify — even if it sounds plausible, even if it's probably true — it gets flagged.
This is the adversarial layer. Gemini doesn't assume Claude got it right.
It checks.
And if the validation fails? The draft goes back to Phase 4 for refinement. No exceptions.
Most agencies skip this step entirely. They assume one AI is good enough. Or they rely on a human editor who doesn't have time to verify every source.
We don't.
Phase 3 is non-negotiable. If Gemini doesn't pass the draft, it doesn't publish.
Phase 4: Claude Refinement
Claude revises based on Gemini's feedback.
If Gemini flagged a claim that can't be verified, Claude removes it or rewrites it with a traceable source.
If a statistic drifted during paraphrasing, Claude corrects it to match the original data.
This phase isn't about rewriting the whole article. It's about surgical corrections — fixing the specific gaps Gemini identified without breaking the narrative flow.
Once Claude completes the revisions, the content loops back to Gemini for a final validation pass.
If it clears, it moves to publication.
If it doesn't, it goes back to Phase 4 again.
The content doesn't ship until both engines agree it's accurate.
| Phase | AI Engine | Action | Output | Quality Gate |
|---|---|---|---|---|
| Phase 1: Research | Gemini | Validate all sources against institutional databases, build verified research brief | Research brief with verified external evidence, direct answer directive, FAQ seeds | Every source must trace to Tier 1 or Tier 2 institutional publisher |
| Phase 2: Drafting | Claude | Draft article using verified research brief, integrate voice and POV, address all intent layers | Complete draft with structure, narrative, and strategic positioning | Must stay within verified claim boundaries set by Gemini |
| Phase 3: Re-Validation | Gemini | Audit draft, cross-check every claim against original sources, flag unverifiable assertions | Validation report with flagged errors or approval to proceed | Zero unverifiable claims permitted — draft fails if any claim can't be traced |
| Phase 4: Refinement | Claude | Revise flagged sections, correct drift, remove or replace unverifiable claims | Final draft ready for publication | Must pass Gemini's final validation before content ships |
Why This Matters for Chiropractic Practices
Healthcare content carries weight most industries don't deal with.
When you publish an article about email marketing, a factual error is embarrassing.
When you publish an article about spinal manipulation techniques and get the contraindications wrong, someone could get hurt.
AI engines know this. Patients know this.
And the gap between practices that take accuracy seriously and practices that don't is widening fast.
The Two-AI Validation System isn't about being clever with content. It's about protecting your reputation and building the kind of authority that earns patient trust and AI citations.
AEO content writing at scale requires both volume and precision. Most agencies can deliver one or the other. We engineer both.
Patient Safety Starts With Accurate Information
Patients searching for chiropractic care are looking for answers they can trust.
When they land on your site and read an article about treatment options, they're not just evaluating your writing style. They're evaluating whether you know what you're talking about.
If the information is vague, generic, or contradicts what their primary care physician told them — they leave.
And they don't come back.
The ethical responsibility of publishing healthcare content is higher than most industries. NIH's health literacy standards emphasize that clear, accurate, and easy-to-understand health information is a public health necessity.
When we validate every claim in your content against institutional sources, we're not just optimizing for AI engines.
We're protecting the patients who will read that content and make treatment decisions based on what they learn.
That's not a marketing tactic. That's basic professional responsibility.
AI Engines Prioritize Verifiable Content
When ChatGPT, Gemini, or Perplexity evaluates content for citation eligibility, they're looking for the same thing human fact-checkers look for.
Sources.
Can this claim be traced to an institutional database?
Does the statistic match published research?
Is the clinical recommendation aligned with established guidelines?
If the answer is no — or if the AI can't confirm it — your content doesn't get cited.
It gets filtered out.
Answer Engine Optimization (AEO) is about structuring content so AI engines can extract, verify, and cite it. But if the underlying claims aren't verifiable, the structure doesn't matter.
You can have perfect schema, clean internal linking, and a semantically optimized content hierarchy — and still be invisible if AI engines can't confirm what you're saying is true.
The Two-AI Validation System ensures that every claim we publish can be traced.
That's the foundation of citation eligibility.
The Competitive Gap This System Creates
Most chiropractic practices publishing AI content right now are using generic ChatGPT prompts with zero validation.
They're not fact-checking. They're not verifying sources. They're not engineering precision.
They're treating content like a checkbox.
Publish 12 blog posts this year. Check. Move on.
That creates a permanent authority gap.
When you're publishing content that's verified, fact-checked, and traceable — and your competitor is publishing generic AI output that sounds good but can't be confirmed — AI engines make a choice.
They cite the verified content. They ignore the unverified content.
The way AI is changing patient discovery isn't theoretical anymore. Volume without accuracy is noise. The practices that understand this early are the ones locking in the authority signals that compound over time.
The practices that don't?
They're invisible. And every month they stay invisible, the gap gets harder to close.
| Content Type | Validation Process | Citation Risk | Entity Trust Impact | AI Recommendation Likelihood |
|---|---|---|---|---|
| Generic AI Blog Posts | None — single AI writes and validates its own output | High — unverified claims reduce citation eligibility | Low — AI engines cannot confirm entity expertise | Very Low — fails verification layer most engines use |
| Template SEO Articles | Human editorial review only | Moderate — depends on editor's subject matter expertise | Moderate — entity signals present but weak verification | Low — competing with stronger verified content |
| Two-AI Validated Content | Multi-phase validation with institutional source verification | Low — every claim traceable to Tier 1/2 sources | High — verified accuracy builds entity trust over time | High — passes AI verification and citation eligibility tests |
What Makes This System Different From Standard AI Content
AI content is everywhere now.
Every agency offers it. Most charge $200–$500 per article and call it a premium service.
Here's what you're actually getting: a ChatGPT prompt, a quick human edit for tone, and a publish button.
No research brief. No source validation. No adversarial review layer.
Just volume.
And volume without precision is how you stay invisible.
Most Agencies Use One AI and Call It Done
The standard agency workflow looks like this:
Freelance writer gets a topic. Opens ChatGPT. Asks it to write 1,500 words on "benefits of chiropractic care for lower back pain." Copies the output. Does a quick pass for readability. Publishes.
Total time: 45 minutes.
No verification of clinical claims. No fact-checking of statistics. No institutional source validation.
If ChatGPT says "studies show that 80% of patients experience relief within two weeks," the writer assumes it's true and moves on.
They don't check if that statistic exists. They don't confirm which study it came from. They don't verify the methodology.
Generic AI prompts produce generic AI output. And generic output doesn't build authority.
It fills space.
AI engines see right through it. When they can't verify the claims, they don't cite the content. And when they don't cite the content, you're not the answer.
The "AI Content" You're Being Sold Is a Commodity
If you think you can replicate the Two-AI Validation System with a weekend and a ChatGPT subscription — you can't.
This is an engineered system, not a prompt library.
The value isn't just using two AIs. It's the proprietary validation loops, the institutional source verification protocol, the refinement methodology that catches errors before publication.
The DIY Underestimator looks at this and thinks, "I could set that up myself."
Then they try.
And three months later, they're still publishing unverified content because they don't have the infrastructure to validate at scale.
This isn't about adding words to a page. It's about engineering precision in a process most agencies treat as a commodity.
White-glove execution means you don't manage the complexity. You don't build the prompts. You don't validate the sources. You don't audit the drafts.
We do.
And the output you get is accurate, verified, and structured to build the kind of authority AI engines trust.
Authority Requires Engineering, Not Just Execution
Here's the objection I hear most often: "This sounds expensive. Can't I just hire a good writer and skip the AI entirely?"
You can.
And you'll get one article every two weeks instead of twelve articles per month.
The system we built doesn't replace human oversight. It scales it.
AI handles the research volume, the drafting speed, and the structural execution. The validation framework we engineered ensures the output meets expert-level standards for accuracy.
Human experts write great content. But they can't produce the volume AI engines need to see before they classify you as an authority in your market.
Authority isn't built with one great article.
It's built with twelve great articles per month, every month, for twelve months — all verified, all traceable, all structured to reinforce entity trust.
That's what the Two-AI Validation System delivers.
Volume and precision. At the same time.
Frequently Asked Questions
Why can't you just use ChatGPT-4 like other agencies?
Because ChatGPT-4 — or any single AI model — acts as both writer and fact-checker.
That creates a blind spot.
When the same engine that wrote the claim is also validating the claim, there's no external verification layer. The model can confidently generate false information and then confirm that false information sounds plausible.
ChatGPT can research fine. But asking one AI to validate its own output? Structurally broken.
The Two-AI Validation System introduces an adversarial layer. Gemini doesn't trust Claude's draft. It checks every claim against institutional sources before approving publication.
That tension — between the AI that wrote and the AI that validates — is what catches errors single-model workflows miss.
Does this Two-AI System make the content creation process slower or more expensive?
It makes the process more rigorous. Not necessarily slower.
The speed comes from building accuracy upfront instead of fixing errors after publication.
When agencies publish unverified AI content, they're not saving time. They're deferring the cost of accuracy to a moment when it's more expensive to fix — after patients have read the misinformation, after AI engines have crawled the bad data, after the reputation damage has already happened.
Engineering precision at the research phase prevents costly rewrites later. That's the efficiency.
As for cost — yes, this system requires more infrastructure than a single ChatGPT prompt. But the alternative is publishing content that doesn't build authority, doesn't earn citations, and doesn't convert patients.
Volume without verification is just noise.
And noise doesn't compound.
How does this system specifically help a chiropractor?
For chiropractors, patient trust is everything.
When someone searches for chiropractic care, they're not just looking for a clinic. They're looking for someone they can trust with their health.
If the content on your site contains inaccurate claims — even small ones — that trust is gone.
Patients don't give you the benefit of the doubt. They close the tab and Google someone else.
The Two-AI Validation System ensures that every piece of health information published on your site is fact-checked and traceable to institutional sources.
That protects your reputation. It protects your patients.
And it builds the kind of entity trust AI engines prioritize when deciding who to recommend.
When AI engines see verified, accurate content consistently published under your entity — they classify you as an authority.
Not because you gamed an algorithm. Because you earned it.
Isn't it easier to just have a human expert write everything?
Easier? Yes.
Scalable? No.
A human expert can write one great article every week or two. AI can draft twelve articles per month. The validation framework we built ensures the AI's output meets expert-level standards for accuracy.
The goal isn't to replace human expertise. It's to scale it.
AI handles the volume. The Two-AI Validation System handles the quality control. Human oversight ensures the strategic intent and voice stay consistent.
That combination — AI for scale, engineered validation for accuracy, human framework for strategic positioning — is how you build authority at the speed AI engines require.
Can I just set up my own two-AI system?
You can try.
But the value isn't just using two AIs. It's the proprietary prompts that tell Gemini how to validate sources. It's the validation loops that catch errors before publication. It's the refinement methodology Claude uses to fix flagged claims without breaking narrative flow.
That infrastructure took months to engineer. It's not a weekend project.
And even if you replicate the structure, you still have to manage the execution. You still have to run the validation audits. You still have to refine the drafts when Gemini flags errors.
The white-glove service we offer means you don't touch any of that.
You approve topics. You review the final content.
Everything in between — the research, the drafting, the validation, the refinement — happens without you.
The system works because we built it to run without requiring the client to become an AI prompt engineer.
How does this system prevent AI hallucinations?
AI hallucinations happen when a model generates plausible-sounding information that isn't grounded in verifiable data.
Single-AI workflows can't catch this. The model that wrote the claim is the same model validating the claim.
The Two-AI Validation System prevents hallucinations by introducing an external validation layer.
Gemini validates all sources at the research phase. If a source can't be confirmed against an institutional database, it doesn't go in the brief.
Then, after Claude drafts the article, Gemini re-validates every claim in the draft. If Claude introduced something Gemini can't verify — even if it sounds true — it gets flagged and removed.
That multi-pass verification is what stops hallucinations from reaching publication.
The second AI doesn't trust the first AI. It checks.
What happens if Gemini flags an error in Claude's draft?
Claude revises.
If Gemini identifies a claim that can't be verified, Claude removes it or rewrites it with a traceable institutional source.
If a statistic drifted during paraphrasing, Claude corrects it to match the original data exactly.
This is Phase 4 — refinement. It's a surgical fix, not a full rewrite.
Once Claude completes the corrections, the content loops back to Gemini for a final validation pass.
If it clears, it moves to publication.
If it doesn't, it goes back to Phase 4 again.
No content ships until both engines agree it's accurate. No exceptions.
Does this guarantee my content will be cited by AI engines?
No.
We don't guarantee citations. We guarantee verified accuracy.
Citation eligibility requires more than just factual content. It requires entity trust, semantic density, internal linking architecture, and consistent publishing velocity.
But verified accuracy is the foundational requirement. If AI engines can't confirm your claims, the rest doesn't matter.
The Two-AI Validation System ensures that every claim we publish is traceable to an institutional source.
That's the first gate. Everything else builds on top of it.
Conclusion
AI content without validation is a liability, not an asset.
The marketing industry jumped on generative AI fast — not because they engineered better processes, but because it was cheaper and clients asked for it.
Most agencies are publishing volume with zero verification.
That's not strategy. That's hopium.
The Two-AI Validation System is how we engineer the kind of precision healthcare content requires.
This isn't about being clever with prompts. It's not about using AI to cut costs. It's about building the kind of verified, fact-checked authority that AI engines trust enough to cite — and patients trust enough to act on.
When you're publishing information that people use to make health decisions, "pretty close" isn't good enough.
Every claim needs a source. Every source needs to be institutional. And every piece of content needs to pass validation before it reaches publication.
That's the standard.
And the practices that meet it early are the ones locking in the authority signals that compound over time.
The practices that don't? They're publishing content that looks fine, sounds plausible, and gets completely ignored by the AI engines making recommendations in their market.
There's no version of this where doing nothing is a safe play.
AI is already making recommendations. Either your content is verified enough to be cited, or a competitor's is.
Want to see how your current content stacks up against the kind of verified, fact-checked execution AI engines prioritize? The AI Visibility Check takes 15 minutes and shows you exactly what ChatGPT, Gemini, and Grok say when someone asks who to trust in your market.
621 Enterprises, Inc. | Copyright 2026 | All rights reserved