
Measuring Answer Dominance: How to Track Your AEO Performance
Most chiropractors think they're tracking performance. They're not. They're looking at traffic dashboards built for a game that ended six months ago. Tracking AEO performance means systematically querying multiple AI engines with specific, intent-driven prompts to discover where your business appears, how you're positioned, and whether you're being recommended over competitors. This is manual discovery work — not automated reporting. You're measuring real authority signals like entity recognition, recommendation quality, and competitive positioning across ChatGPT, Gemini, and Grok.
The reason this can't be automated is simple: AI engines don't provide a public API for citation tracking. Any tool claiming to show you how many times AI cited your business is selling you a metric they can't verify. They're guessing. And you're paying them to guess. The fundamental shift from keyword searching to conversational querying has created an entirely new measurement paradigm that existing tools weren't built to measure.
What you're tracking isn't traffic. It's not keyword rankings. It's trust. When someone asks ChatGPT who the best chiropractor in their area is, does your name appear? Are you recommended first, or are you buried in a list with five competitors? Are you mentioned at all? That's answer dominance. And the only way to measure it is to ask the questions yourself, systematically, and document what comes back. Research shows that two-thirds of Google searches already ended without a click — and that trend accelerates exponentially with AI-native interfaces.
This article breaks down the exact methodology for tracking your AI visibility, what signals matter, what to ignore, and how to use this data to inform your ongoing AEO strategy. If you've been burned by agency reports that showed you vanity metrics instead of patient bookings, this is the framework that separates real performance from hopium.
Last Updated: April 27, 2026
Why Traditional Metrics Don't Work for AEO
SEO gets you on a list. AEO gets you named as the answer.
Those aren't variations of the same thing.
For twenty years, the game was traffic. More clicks meant more patients. Higher rankings meant more bookings. That model worked when Google showed ten blue links and users clicked through to compare options. But AI engines don't show options. They show verdicts. And if you're not the verdict, the traffic you're generating doesn't matter — because users aren't comparing anymore.
Most chiropractors are still measuring success with dashboards built for the old game. Page views. Bounce rates. Time on site. These are metrics that made sense when the decision happened on your website. Now the decision happens inside the AI interface before anyone clicks. ChatGPT recommends a name. The patient books. Your traffic numbers never enter the equation.
The Traffic Mirage
I've seen practices generating 10,000 monthly visitors celebrate their "SEO success" while ChatGPT and Gemini recommend their competitors by name.
That traffic isn't converting like it used to. Not because the website's broken. Because fewer people are arriving at websites through traditional search in the first place.
The zero-click search trend isn't slowing down. It's accelerating. AI-native interfaces eliminate the need to click at all. Users ask a question. They get an answer. If that answer names your competitor and not you, your 10,000 monthly visitors are irrelevant. You're not in the conversation that matters.
The future isn't about getting users to your site. It's about being named before they ever leave the AI interface.
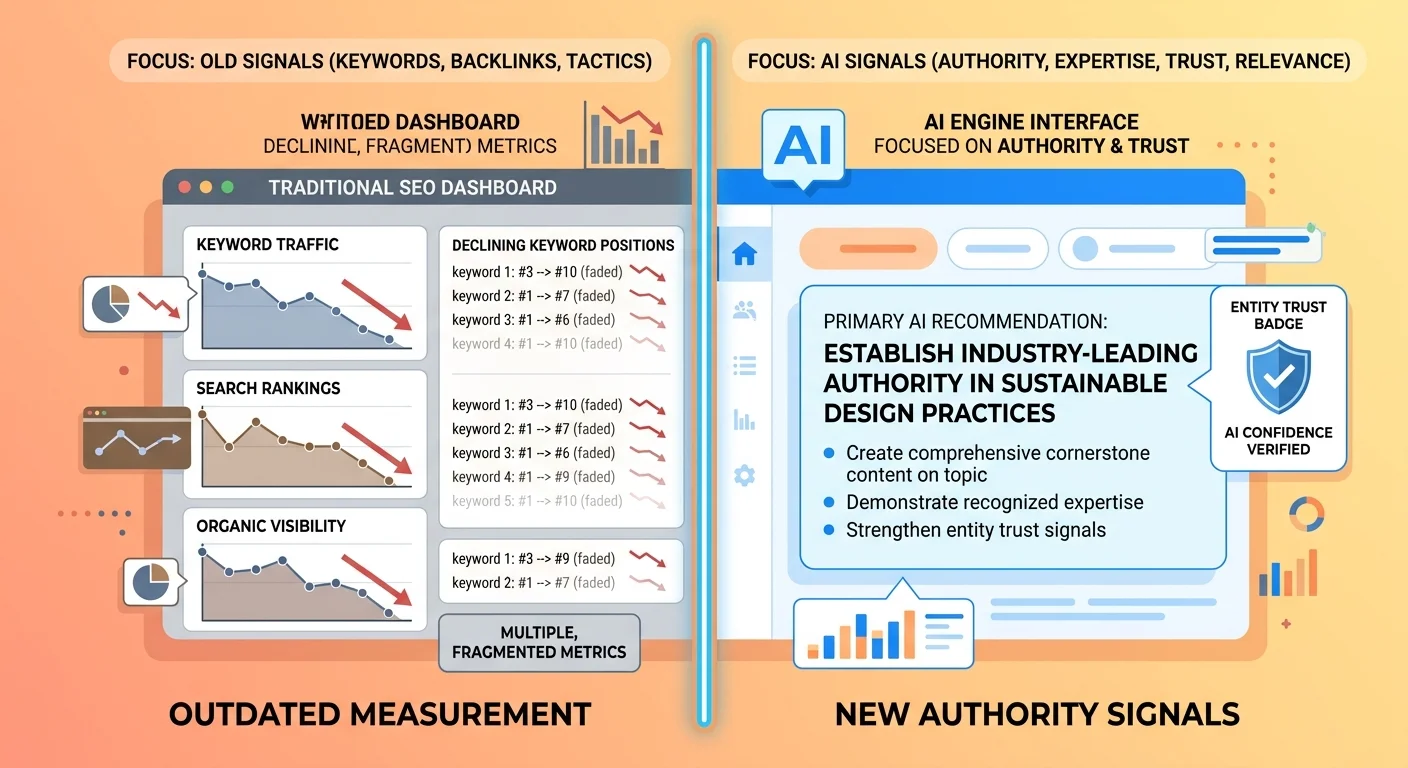
Authority Signals vs. Vanity Metrics
| Metric Type | What It Measures | Why It Matters (or Doesn't) |
|---|---|---|
| Page Views (SEO) | How many times users loaded pages on your site | Declining relevance in zero-click AI environments where recommendations happen without site visits |
| Keyword Rankings (SEO) | Where your pages appear in a list of search results | Irrelevant when AI presents a single recommended answer instead of a ranked list |
| Entity Recognition (AEO) | Whether AI engines understand your business as a verified entity with accurate attributes | Foundational — if the engine doesn't recognize you as a real business, you can't be recommended |
| Recommendation Quality (AEO) | How you're positioned when mentioned — as the primary answer or as one of several options | Direct measure of trust — primary recommendations convert, list inclusions don't |
| Competitive Positioning (AEO) | Where you appear relative to competitors when AI answers commercial intent queries | Shows whether your authority is compounding or eroding over time |
| Citation Context (AEO) | The surrounding language when you're mentioned — positive endorsement or neutral listing | Reveals depth of trust — "I recommend [name]" vs "here are some options including [name]" |
Entity recognition, recommendation quality, competitive positioning, citation context — these aren't proxies for authority. They are authority.
Contrast that with what agencies have historically sold. Impressions measure how many times a link appeared. Clicks measure how many users followed it. Time on site measures how long they stayed. These were useful when users compared options manually. Now they're measuring activity that happens after the critical decision — which AI engine recommended you in the first place.
According to Search Engine Journal's analysis of 200,000 queries, AI engines synthesize information from multiple sources to form a single consensus answer. If you're not contributing to that consensus through verified entity signals and authoritative content, you're invisible — regardless of your traffic.
Here's the kicker: you can have 10,000 visitors a month and still be invisible if ChatGPT doesn't know your name when someone asks for a recommendation. Traffic was the currency of the old internet. Trust is the currency now. And trust is measured by whether AI engines cite you — not whether users click through to your site. McKinsey's research shows that brand authority and trust have become the key differentiators for AI recommendation — not marketing spend, not traffic, not traditional SEO tactics.
The Problem with Automated AI Citation Tools
A new category of tools is emerging. They promise to track how many times AI engines cite your business. Monthly dashboards. Citation counts. Recommendation frequency. Competitive comparisons.
It's the next evolution of agency snake oil.
The pitch sounds compelling. "Finally, you can measure your AI visibility with real data." But here's the problem: that data doesn't exist in a reliable, trackable format. ChatGPT, Gemini, and Grok don't provide public APIs that let third parties query citation frequency. These tools are selling you metrics they can't actually verify.
Why AI Citation Tracking Is the New Snake Oil
These tools are selling you a lie. Not a small one. A foundational one.
They're claiming to measure something that can't be measured reliably because the data doesn't exist in a structured format. ChatGPT, Gemini, and Grok don't provide APIs that let third parties track citation frequency or verify source attribution. What these tools are doing instead is scraping, estimating, or using proxy signals that have nothing to do with what real users actually see.
The reason this matters isn't just that the data's unreliable. It's that practitioners are making strategic decisions based on fabricated metrics. You're being told you got "500 AI citations this month" when in reality, that number is extrapolated from a model that has no way to verify whether those citations appeared in real queries, whether they were positive recommendations, or whether they even mentioned your business accurately.
It's the same playbook agencies used with traditional SEO. Sell a metric that sounds impressive, can't be easily verified, and keeps the client paying monthly. The only difference now is they're calling it "AI citation tracking" instead of "keyword rankings."
I've watched practices pay for these tools, see impressive dashboards with hundreds of "AI citations," and then run a manual check only to discover ChatGPT doesn't mention them at all. The disconnect isn't subtle. It's total. The tool showed data. Reality showed invisibility.
That's not a measurement error. That's fabrication.
What These Tools Are Actually Measuring
| Tool Claim | Likely Data Source | Why It's Unreliable |
|---|---|---|
| "500 AI citations this month" | Scraped web mentions or backlink proxies extrapolated into a projection | No verification that these mentions appeared in actual AI responses to user queries |
| "80% recommendation rate" | Proprietary model estimation based on incomplete data | No access to live AI engine query results or recommendation context |
| "Ranked #1 in your market" | Comparative analysis using the same unreliable scraping methods | Rankings assume consistent data when the underlying measurement is fabricated |
| "Citation velocity trending up" | Week-over-week comparison of proxy metrics | Changes could reflect scraping inconsistencies rather than actual visibility shifts |
At best, these tools are measuring indirect activity. Web mentions. Backlink frequency. Directory listings. These are inputs into entity trust — not measures of AI recommendation.
At worst, they're measuring nothing at all and generating numbers designed to look authoritative.
The fundamental problem isn't that the methods are imperfect. It's that they're selling certainty where certainty doesn't exist. You can't track AI citations reliably without access to live query data from the engines themselves. And that data isn't available. Not to these tools. Not to anyone.
If a tool promises to show you how many times ChatGPT cited your business last month, you're not looking at real data. You're looking at a model's guess dressed up as a report. And strategic decisions based on guesses compound into wasted execution.
The Manual Discovery Framework

There's only one legitimate methodology for tracking AI visibility: manual, systematic querying of AI engines using real prompts that mirror actual user intent.
This isn't a shortcut. It's rigorous, repeatable discovery work.
You ask the questions patients would ask. You document the responses. You track changes over time. You compare competitive positioning. You identify patterns.
It's the only method that measures what actually happens when a real user queries an AI engine for a recommendation.
Quick reality check: If you think tracking this is just running a few prompts on ChatGPT, this isn't for you. That's a spot check, not a system. This is a rigorous process, and it requires discipline. If you're looking for a quick checklist you can knock out in an afternoon, you're in the wrong place. No hard feelings.
Building Your Prompt Set
The first step is constructing a test set of prompts that mirror real user intent.
Not hypothetical questions. Not keyword-stuffed queries. The actual language patients use when asking AI engines for recommendations.
There are three categories, and each tests a different layer of your authority infrastructure:
Navigational prompts — "Who is [your business name]?" / "Tell me about [your practice name] in [city]." These test entity recognition. If the engine can't accurately describe who you are, your entity signals are weak.
Informational prompts — "What's the best treatment for sciatica in [city]?" / "How do chiropractors treat lower back pain?" These test semantic depth. If the engine doesn't cite you when answering treatment questions, your content lacks the authority density needed for topical trust.
Commercial prompts — "Recommend a chiropractor near me." / "Who's the best chiropractor in [city] for sports injuries?" These test recommendation quality. This is where answer dominance shows up. Are you the name AI says to trust, or are you buried in a list with five competitors?
Build a prompt set with at least 15–20 queries covering all three categories. Weight it toward commercial prompts — those are the queries that drive bookings. But include navigational and informational prompts to diagnose gaps in entity trust and content authority.
| Prompt Type | Example | What It Tests | Frequency |
|---|---|---|---|
| Navigational | "Who is [Your Practice Name]?" | Entity recognition and attribute accuracy | 2–3 prompts per test cycle |
| Informational | "What's the best treatment for sciatica in [City]?" | Semantic authority and topical depth | 5–8 prompts per test cycle |
| Commercial | "Recommend a chiropractor near me for sports injuries" | Recommendation quality and competitive positioning | 8–12 prompts per test cycle |
This isn't guesswork. The structure of your prompt set determines what you can measure. A set heavy on navigational prompts will tell you if AI knows you exist. A set heavy on commercial prompts will tell you if AI trusts you enough to recommend you.
Build for the insights you need.
Testing Across Multiple Engines
ChatGPT, Gemini, and Grok each have different trust models and data sources.
Testing all three matters because a strong result in one engine and weak results in the others tells you where your authority infrastructure has gaps.
ChatGPT prioritizes conversational context and synthesized knowledge. If it doesn't mention you, your content lacks semantic density. Gemini leans heavily on structured data and verified entity signals. If Gemini can't describe your business accurately, your schema and directory profiles are incomplete. Grok pulls from real-time social signals and web mentions. If Grok doesn't cite you, your brand presence across external platforms is weak.
Testing all three gives you a diagnostic map. You're not just measuring whether you're visible — you're measuring why you're visible (or invisible) and what layer of your infrastructure needs strengthening.
The differences in results also reveal which engines are compounding your authority faster. If ChatGPT starts recommending you six months before Gemini does, that tells you your content execution is working but your entity signals need work. If Gemini cites you accurately but ChatGPT never mentions you, the inverse is true.
Cornell University's research on entity-based search shows that AI models rely on understanding entities to provide authoritative answers. If your entity isn't well-defined across the data sources these engines trust, you won't appear in their recommendations. Testing across engines surfaces exactly where that definition breaks down.
This is what an AI Authority Engine does — the infrastructure layer that ensures every AI engine can recognize, trust, and recommend your business consistently.
Documenting Results
Tracking isn't tracking unless you're documenting.
That means a structured tracking sheet — not mental notes, not screenshots saved somewhere, not "I checked ChatGPT last week and I think I saw my name."
Your documentation needs five fields: date, engine, prompt, result, and competitive positioning.
Date — When you ran the test. This is how you measure compound growth.
Engine — ChatGPT, Gemini, or Grok. Each gets its own row.
Prompt — The exact query you used. Word-for-word. You'll rerun this exact prompt in future cycles.
Result — Mentioned or not mentioned. If mentioned, was it a primary recommendation or a list inclusion? Copy the exact language the engine used.
Competitive Positioning — If competitors were mentioned, who appeared and in what order? This tells you whether your authority is compounding or eroding relative to your market.
Run this process quarterly. That's frequent enough to catch major shifts but infrequent enough that you're measuring compound growth instead of noise. Monthly spot checks on your highest-priority commercial prompts are fine for monitoring, but the strategic insights come from comparing quarterly snapshots.
The data layer you're building here is the only honest measure of AEO performance. It's manual. It's time-consuming. And it's the only method that reflects what real users actually see when they ask AI engines for recommendations.
What Answer Dominance Actually Looks Like

There are three levels of visibility in AI answer engines. Most practices don't understand the difference — and that's why they think they're winning when they're actually stuck in the middle tier going nowhere.
Tier 1: Not mentioned. The AI engine doesn't cite your business at all. You're invisible. This is where weak entity signals and thin content authority show up. If you're here, the problem isn't marketing tactics. It's infrastructure.
Tier 2: Mentioned in a list. The AI engine includes your name alongside three to five competitors. "Here are some chiropractors in your area: [Competitor A], [Competitor B], [Your Name], [Competitor C]." You're visible, but you're not trusted. This is inclusion, not recommendation.
Tier 3: Recommended as the answer. The AI engine names you specifically as the primary recommendation, often with context explaining why. "Based on patient reviews and treatment specialization, I'd recommend [Your Name]." This is answer dominance.
Only Tier 3 reflects real authority.
Most practices celebrating their "AI visibility" are stuck in Tier 2, thinking they've won because their name appeared somewhere in the response.
The gap between Tier 2 and Tier 3 isn't subtle. It's the difference between being an option and being the verdict. Patients don't evaluate options the way they used to. They trust the recommendation and book. If you're not the recommendation, you're not in the decision.
Entity Recognition
The baseline. Does the AI engine know your business exists as a verified entity?
Can it pull your name, location, and service category accurately? If this fails, nothing else matters.
Entity recognition isn't about whether a search engine has indexed your website. It's about whether the AI engine understands your business as a real, trustworthy entity with verified attributes. Name, address, phone, hours, services, credentials — all of it structured and consistent across the data sources AI engines trust.
If you run a navigational prompt — "Who is [Your Practice Name]?" — and the engine can't answer accurately, you have an entity trust problem. That's the foundational layer. Without it, the engine has no anchor point to build topical authority around. You're just noise.
This is where weak infrastructure shows up first. Missing schema. Inconsistent NAP across directories. No verified Google Business Profile. The engine is trying to verify you exist, and the signals contradict each other. So it doesn't cite you at all.
Recommendation Quality
Being mentioned isn't the same as being recommended.
Here's what Tier 2 looks like:
"Here are some chiropractors in [City]: [Competitor A] specializes in sports injuries, [Competitor B] has evening appointments available, [Your Name] offers family chiropractic care, [Competitor C] focuses on pediatric care."
Your name appeared. The engine recognizes you. But there's no endorsement. No prioritization. No reason for the patient to choose you over the other four names in that list.
Now here's what Tier 3 looks like:
"Based on patient reviews and expertise in treating sciatica, I'd recommend [Your Name]. They've been practicing in [City] for [X years] and specialize in evidence-based treatment protocols for lower back pain."
That's not inclusion. That's a verdict.
The engine isn't presenting options. It's making a recommendation. And the patient reading that response isn't comparing five websites. They're booking with the name AI told them to trust.
The difference between those two responses is authority depth. Tier 2 means the engine knows you exist. Tier 3 means the engine trusts you enough to stake its credibility on saying your name first.
Most practices are optimizing to get from Tier 1 to Tier 2. They want to be mentioned. But the real gap — the one that determines whether AI visibility turns into patient bookings — is between Tier 2 and Tier 3. That's where ongoing AEO content execution compounds into answer dominance.
Competitive Positioning
When you are mentioned, where do you appear relative to competitors?
First? Third? Not at all?
This is the metric that separates real authority from proximity luck. If you're consistently mentioned first across multiple commercial prompts, your authority is compounding. If you're mentioned third or fourth, you're visible but not trusted. If competitors are mentioned and you're not, you're losing ground every quarter you let that gap widen.
Track this over time and you'll see patterns. Early in your AEO execution, you might not appear at all. Three months in, you start showing up in lists. Six months in, you're mentioned alongside two competitors instead of five. By twelve months, you're the primary recommendation and competitors are the ones buried in the list.
That progression is compound authority.
And the only way to measure it is to document competitive positioning in every test cycle. Not just "did I appear?" but "who else appeared, in what order, and how was I framed relative to them?"
If your quarterly tracking shows you moving from Tier 2 to Tier 3 while competitors stay in Tier 2, that's proof your execution is working. If it shows you stuck in Tier 2 for six months while a competitor moves to Tier 3, that's a signal to audit your content depth and entity trust immediately.
The practices that track competitive positioning quarterly know exactly where they stand. The ones that don't are guessing — and in a market where AI recommendations compound every month, guessing is the same as losing.
Tracking Competitive Positioning Over Time
Authority compounds. But you can't measure compounding without a time axis.
That's why quarterly tracking is the right cadence — frequent enough to catch major shifts, infrequent enough to see real patterns instead of noise.
Monthly spot checks are fine for monitoring your highest-priority commercial prompts. If you notice a sudden drop or a competitor appearing where they weren't before, you can investigate immediately. But the strategic insights — the data that tells you whether your execution is working — come from comparing quarterly snapshots.
AI content requires quarterly audits because authority isn't static. It decays if you stop publishing. It strengthens if you maintain execution. Quarterly tracking lets you see that movement clearly.
The Compound Authority Curve
| Quarter | Primary Mentions | Competitive Position | New Entity Signals | Strategic Notes |
|---|---|---|---|---|
| Q1 | 0 out of 12 commercial prompts | Not appearing in any commercial recommendations | Schema deployed, GBP optimized, first 12 AEO articles published | Baseline established — building foundation |
| Q2 | 3 out of 12 commercial prompts | Mentioned in lists alongside 4 competitors, never first | Directory profiles verified, 24 total AEO articles live | Early entity recognition appearing |
| Q3 | 7 out of 12 commercial prompts | Mentioned first in 2 prompts, second/third in 5 others | Knowledge panel appearing, local pack visibility improving | Authority compounding — Tier 2 to Tier 3 transition starting |
| Q4 | 10 out of 12 commercial prompts | Primary recommendation in 8 prompts, second in 2 | Competitors mentioning practice by name in their content | Answer dominance achieved across most commercial intents |
What compound growth looks like: early months show small gains. You're not invisible anymore, but you're not recommended either. You're in Tier 2 — mentioned in lists, not prioritized.
Six months in, you start appearing consistently. List mentions become more frequent. Occasionally, you're cited first instead of third. The entity signals are strong enough that AI engines trust you exist and know what you do.
By twelve months, you're the default recommendation for your core commercial prompts. Competitors are the ones buried in lists now. Patients asking for a chiropractor in your market hear your name first — not because you gamed an algorithm, but because you built the authority infrastructure and content depth AI engines use to determine trust.
This isn't linear. It's exponential.
The first three months feel slow. The next three feel slightly faster. By month nine, the compounding is obvious. And by month twelve, the gap between you and competitors who didn't execute is wide enough that they can't close it without a full infrastructure rebuild.
Quarterly tracking lets you see the curve forming. It also lets you spot when you're stalling — which is the signal to audit your execution and figure out what gap needs closing.
When to Adjust Strategy
If quarterly checks show you're stalling or losing ground, that's the signal to audit your content execution and authority infrastructure.
Are you publishing consistently? Are you maintaining entity signals across directories? Are competitors outpacing you because they started executing while you waited?
The data tells you where the gap is.
If you're stuck in Tier 1 (not mentioned at all), the problem is entity recognition. Your schema is incomplete, your directory profiles are inconsistent, or AI engines can't verify you exist as a real business. Fix the foundation before adding content.
If you're stuck in Tier 2 (mentioned in lists but never recommended first), the problem is authority depth. You have entity trust, but your content lacks the semantic density AI engines need to prioritize you. This is where the transition from search keywords to answer clusters matters — you're not writing for rankings anymore, you're writing to build topical authority AI engines can trust.
If you were in Tier 3 and dropped back to Tier 2, the problem is maintenance. Your competitors kept publishing and you stopped. Or they strengthened their entity signals while yours decayed. Authority isn't permanent. It requires ongoing execution. Quarterly tracking surfaces decay early enough to fix it before it becomes a crisis.
The practices that adjust strategy based on quarterly data compound faster because they're not guessing. They know exactly what's working and what's not. They close gaps systematically instead of throwing tactics at a wall.
Using AEO Data to Inform Content Strategy
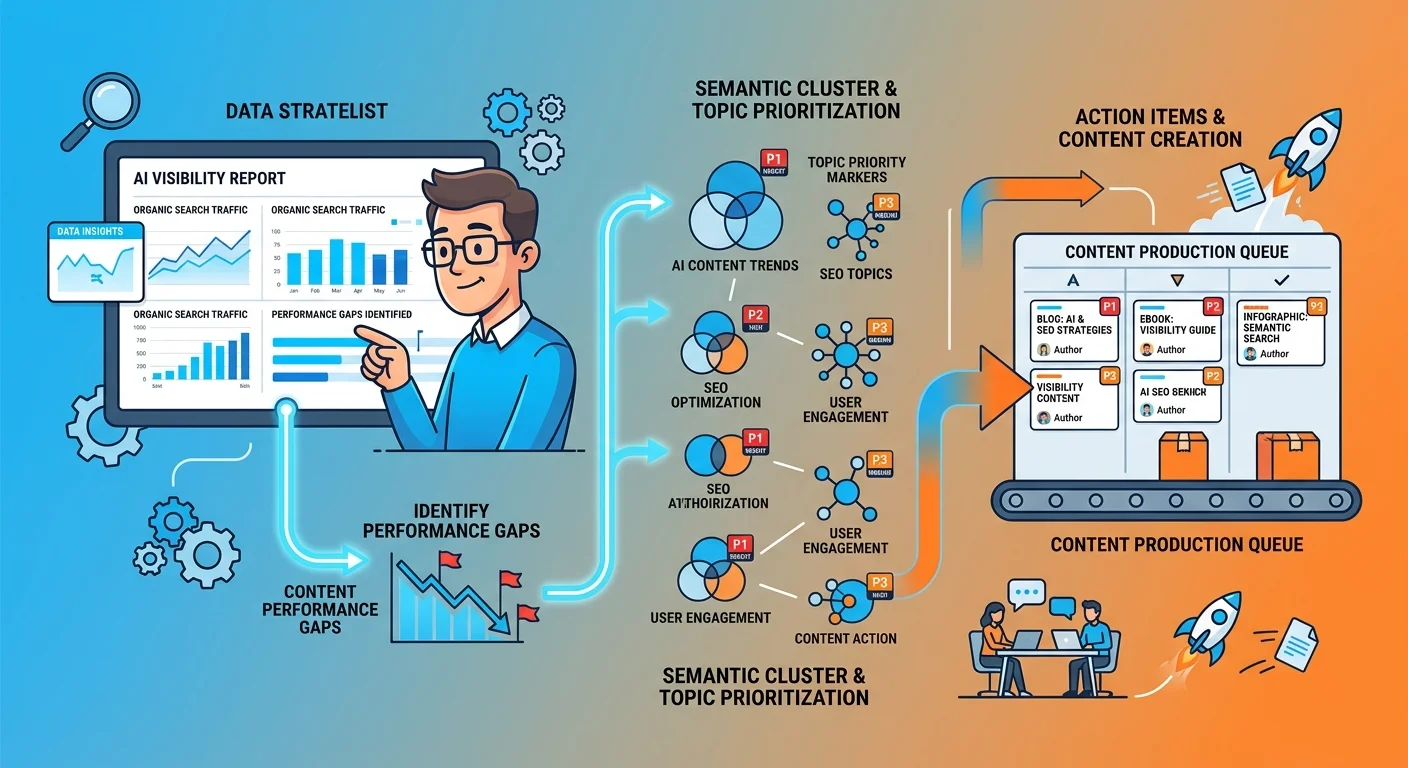
The tracking data isn't just proof of performance. It's the strategic input that tells you what content to write next.
If you're not appearing for commercial intent prompts, that's a signal to strengthen your service-level authority. If you're mentioned but not recommended, that's a depth gap — you need more semantic density around the topics where AI engines are evaluating trust.
This is where most practices fail. They track performance, see gaps, and then... keep publishing whatever they feel like writing. Random blog topics. Generic advice articles. Content that doesn't address the specific authority gaps the data revealed.
Strategic AEO execution means using your tracking data as a roadmap. Where are you invisible? What prompts return competitors but not you? Those gaps are your content priorities.
Systematic tracking reveals exactly which semantic clusters need deeper coverage.
Identifying Authority Gaps
Run your quarterly tracking. Look at the commercial prompts where you're not appearing.
What topics are those prompts asking about?
If patients are asking "recommend a chiropractor for sports injuries" and your name doesn't appear, that's not a traffic problem. It's an authority gap. AI engines don't trust your depth on sports injury treatment. You might have a page on your site about it. You might even rank for some related keywords. But the topical authority isn't strong enough for AI to cite you when someone asks that specific question.
The fix: publish content that closes that gap. Not one article. Multiple. Cover the topic from every angle. Treatment protocols. Recovery timelines. Contraindications. Build the semantic cluster AI engines need to see before they'll trust you as the authority on sports injury chiropractic care.
This isn't guessing. The tracking data told you exactly where the gap is. Now you're filling it systematically.
Prioritizing High-Intent Topics
Not all queries are equal.
Commercial intent prompts — "recommend a chiropractor near me" — matter more than informational ones — "what is a chiropractor." Because the former is where patients make decisions. The latter is where they learn.
Use your tracking data to prioritize content that closes the gaps where patients are actually making decisions.
If your informational prompt results are strong but your commercial prompt results are weak, that tells you something specific: AI engines trust your topical knowledge but not your service-level authority. You're being cited when patients ask "how does chiropractic work" but not when they ask "who should I see."
That's a conversion gap, not an awareness gap.
The fix: shift content production toward service-level authority. Case studies. Treatment specializations. Outcome data. The content that proves you don't just understand the topic — you deliver results.
If both are weak, start with informational authority. Build the topical trust first, then layer service-level depth on top. Trying to be recommended for commercial prompts without foundational informational authority is like trying to skip steps in a process that doesn't allow shortcuts.
We use our two-AI validation system to ensure every piece of content we publish meets the factual accuracy and semantic density standards AI engines require. The tracking data tells us what to write. The validation system ensures what we write actually strengthens authority instead of just adding noise.
Measuring the ROI of AEO Execution
But doesn't traffic still matter more than AI mentions?
No. Not anymore.
Traffic was the proxy metric for authority in the era of blue links. You got clicks, you got conversions, you measured ROI based on cost-per-click. That model worked when users compared options manually.
AI recommendations are the direct metric now. When a patient asks ChatGPT who to see and your name is the answer, they don't need to visit five websites and compare. They book. The intermediate steps — site visits, page views, bounce rates — become less relevant when the trust decision happens inside the AI interface before the patient ever clicks.
The ROI of AEO isn't measured in sessions or bounce rates. It's measured in whether you're the name AI says when someone asks.
Track that, and you're tracking the only metric that will matter six months from now. Because the patients who trust AI recommendations aren't clicking through to compare. They're trusting the verdict and calling the number AI provided.
This is why AI gives one answer instead of ten options. The interface model changed. The measurement model has to change with it. Traffic is a lagging indicator. Recommendation quality is the leading one.
The practices tracking AEO performance quarterly know their ROI. They can point to the commercial prompts where they're the primary recommendation and trace those directly to new patient bookings. The ones still measuring traffic are watching a metric that becomes less correlated with business growth every quarter.
You now know what to measure. You know how to measure it. And you know how to use that data to inform execution.
The infrastructure and content that moves these metrics is what building your authority infrastructure delivers — the foundational layer that makes systematic, compound growth possible.
Frequently Asked Questions
What's the difference between AEO metrics and traditional SEO metrics?
SEO gets you on a list. AEO gets you named as the answer. They're not the same thing.
SEO metrics like traffic and keyword rankings measure how you perform in a list of blue links where patients have to compare options. AEO metrics measure authority signals like recommendation quality that determine if you're the single verdict AI delivers.
One gets you considered. The other gets you chosen.
Why can't I use an automated tool to track AI citations?
Because the data doesn't exist in a format automated tools can access reliably.
ChatGPT, Gemini, and Grok don't provide public APIs that allow third parties to track citation frequency, measure recommendation patterns, or verify source attribution. Any tool claiming to show you "how many times AI cited your business" is using one of three unreliable methods:
Scraping — Trying to extract data from AI interfaces programmatically. This violates most platforms' terms of service and produces inconsistent results because the interfaces aren't designed to be scraped.
Proxy metrics — Using indirect signals like backlink counts or directory mentions as stand-ins for AI citations. These inputs might correlate with entity trust, but they don't measure what users actually see when they query an AI engine.
Model projections — Building a proprietary algorithm that estimates citation likelihood based on incomplete data. This produces numbers that look authoritative but can't be verified against real query results.
None of these methods reflect what happens when a real user asks ChatGPT or Gemini for a recommendation. The only way to measure that is to ask the questions yourself, document the responses, and track changes over time. It's manual. It's rigorous. And it's the only honest methodology.
How often should I run an AEO performance check?
Quarterly for strategic insights. Monthly for high-priority spot checks.
Quarterly tracking gives you enough time to see compound growth patterns without measuring noise. Authority doesn't move week-to-week the way traffic or rankings might. It builds in layers. Quarterly snapshots let you compare positioning, document competitive shifts, and see whether your execution is working.
Monthly spot checks on your highest-priority commercial prompts — the 3-5 queries that drive the most patient bookings — let you monitor for sudden changes. If a competitor who wasn't appearing in Q1 suddenly shows up as the primary recommendation in your Q2 check, you want to know that sooner than later.
If you're just starting AEO execution, run a baseline audit now to document where you currently stand. Then check quarterly. After 12 months of execution, you'll have four data points that show the compound authority curve clearly.
What specific prompts should I use to test my AI visibility?
Use a mix of navigational, informational, and commercial prompts. Each category tests a different layer of authority.
Navigational prompts test entity recognition:
- "Who is [Your Practice Name]?"
- "Tell me about [Your Practice Name] in [City]."
- "What services does [Your Practice Name] offer?"
If the engine can't answer these accurately, your entity signals are weak. Fix schema, directory profiles, and Google Business Profile first.
Informational prompts test semantic authority:
- "What's the best treatment for sciatica?"
- "How does chiropractic help with lower back pain?"
- "What should I expect at my first chiropractic appointment?"
If the engine doesn't cite you when answering these, your content lacks topical depth. You need more AEO articles covering conditions, treatments, and patient education topics.
Commercial prompts test recommendation quality:
- "Recommend a chiropractor near me."
- "Who's the best chiropractor in [City] for sports injuries?"
- "Find a family chiropractor in [City]."
This is where answer dominance shows up. If you're not the primary recommendation here, you're not converting AI visibility into patient bookings. This is the category that matters most.
Build a prompt set with 15-20 queries covering all three categories. Weight it toward commercial prompts — those drive revenue. But include navigational and informational prompts to diagnose infrastructure and content gaps.
Run the same prompts every quarter. Consistency lets you measure changes accurately.
If my AI visibility is low, what's the first thing I should fix?
Infrastructure. Not content. Not marketing. Infrastructure.
Low visibility almost always starts with weak entity signals. AI engines can't verify you exist as a real, trustworthy business because your schema is incomplete, your directory profiles are inconsistent, or your Google Business Profile isn't optimized for machine readability.
Run a navigational prompt: "Who is [Your Practice Name]?" If the engine can't answer that accurately — or if it returns outdated information, wrong addresses, or generic descriptions — your entity trust is the bottleneck.
Fix this first:
- Deploy complete schema markup (LocalBusiness, Organization, MedicalBusiness if applicable)
- Verify NAP (name, address, phone) consistency across every directory and platform
- Optimize your Google Business Profile with structured services, hours, categories
- Ensure your website architecture is AI-readable (clear service pages, semantic HTML, internal linking)
Content authority builds on top of entity trust. If the foundation is weak, publishing more articles won't move the needle. AI engines won't cite you as authoritative if they can't first verify you're a real business.
Once entity signals are strong — once navigational prompts return accurate answers — then layer content depth on top. That's when AEO articles compound into recommendation quality.
Most practices skip the infrastructure step and wonder why their content isn't working. The content is fine. The foundation it's sitting on isn't.
Can I track my competitors' AEO performance the same way?
Yes. Same methodology. Document their positioning relative to yours.
When you run your test prompts, note which competitors appear, in what order, and how they're framed. Are they mentioned as primary recommendations or list inclusions? Are they cited more frequently than you, less frequently, or about the same? What language does the AI engine use to describe them?
Track this quarterly alongside your own performance. It gives you competitive context. If you're improving but competitors are improving faster, you're still losing ground. If you're holding steady but competitors are dropping, your execution is working even if the absolute numbers don't look impressive yet.
Competitive positioning data also reveals strategic gaps. If a competitor is consistently recommended for sports injury prompts and you're not, that tells you they've built stronger authority in that semantic cluster. You can either compete directly (strengthen your sports injury content depth) or differentiate (own a different specialization where they're weak).
The practices that track competitive positioning know exactly where they stand relative to their market. The ones that don't are operating blind, hoping their execution is working without verifying it against the only benchmark that matters — the competitors patients are comparing them to.
How long does it take to see measurable improvement in answer dominance?
I won't promise you a timeline. Not because this doesn't work — because authority doesn't run on a microwave schedule.
What I will say: every month of execution builds on the last. The practices that stick with it compound. The ones that quit give that ground to whoever kept going.
Early months show small gains. You're not invisible anymore, but you're not recommended either. You're in Tier 2 — mentioned in lists, not prioritized. Six months in, you start appearing consistently. List mentions become more frequent. Occasionally, you're cited first instead of third. By twelve months, you're the default recommendation for your core commercial prompts.
This isn't linear. It's exponential. The first three months feel slow. The next three feel slightly faster. By month nine, the compounding is obvious. And by month twelve, the gap between you and competitors who didn't execute is wide enough that they can't close it without a full infrastructure rebuild.
What if I'm mentioned but never recommended first?
You have a depth gap. Entity trust is strong enough for inclusion, but semantic density and citation quality aren't strong enough for prioritization.
This is a Tier 2 problem. AI engines know you exist. They understand what you do. But when they evaluate trust — when they decide whose name to say first — you're not the top choice. That means competitors have stronger authority signals in the specific semantic clusters where commercial decisions happen.
The fix: deepen content around your core service topics. Not generic advice articles. Focused, condition-specific, outcome-oriented content that proves expertise.
If you're mentioned in lists for "chiropractor in [City]" but never recommended first, competitors have stronger localized authority. Strengthen local content depth — neighborhood-specific pages, community involvement signals, location-based service descriptions.
If you're mentioned for general prompts but not specialized ones — "recommend a chiropractor" but not "recommend a chiropractor for sports injuries" — you lack specialization authority. Publish focused content proving depth in a specific treatment area.
The tracking data tells you exactly where the gap is. Close it systematically. Most practices stuck in Tier 2 are publishing content that reinforces breadth (we treat everything) instead of depth (we're the authority on this). AI engines prioritize depth. Breadth keeps you in the list. Depth makes you the recommendation.
Conclusion
There's no neutral position here.
Either you're measuring your AI visibility systematically and using that data to inform your strategy, or you're guessing.
The practices that track answer dominance quarterly know exactly where they stand. They know which prompts return their name. They know where competitors are gaining ground. They know what content gaps to close next. They can see compound growth happening because they've documented it.
The practices that don't track are flying blind. They might be publishing content consistently. They might have good entity signals. But without systematic measurement, they have no way to know whether that execution is translating into the outcome that matters — being the name AI says when patients ask for recommendations.
The methodology here isn't complicated. It's manual, systematic, and rigorous. That's why most practices won't do it themselves. They'll either ignore it entirely or pay an agency to fabricate metrics that make them feel good. But if you're reading this and you've been burned by vanity reports before, you already know the difference between real data and hopium.
This is the real data. And once you see it, you'll never trust an automated citation count again.
The gap between knowing your AI visibility and guessing at it widens every quarter. The practices tracking their performance compound. The ones ignoring it fall further behind without realizing it.
You now know how to track it. What you do with that is your call.
Want to know where you actually stand right now — not where a dashboard says you might stand, but where ChatGPT, Gemini, and Grok actually position you when patients ask for recommendations? We run the same manual discovery framework we just walked through. Fifteen minutes. Real prompts. Documented results. No projections, no proxies, no fabricated citation counts. Just the answer to one question: does AI recommend you, or does it recommend your competitors?
621 Enterprises, Inc. | Copyright 2026 | All rights reserved